 SVA System Vertrieb Alexander GmbH
SVA System Vertrieb Alexander GmbH In unserem letzten Blogbeitrag über semantische Suche haben wir ein Modell dargestellt, das die semantische Ähnlichkeit zwischen zwei Sätzen erkennen kann. Diese Eigenschaft haben wir genutzt, um mit unserer Demoapplikation die Vorteile der semantischen Suche aufzuzeigen.
Was hat sich getan?
Die Welt der semantischen Suche hat sich seitdem schnell weiterentwickelt. Es wurde mittlerweile durch Benchmarks deutlich gezeigt, dass die semantische Suche mit Hilfe von neuronalen Netzen, den sogenannten Transformer Modellen, der klassischen Suche (BM25, TF-IDF) deutlich überlegen ist (https://arxiv.org/pdf/2104.08663.pdf). Zudem gibt es inzwischen zahlreiche neue Modelle, die sich explizit auf die Verbesserung der Suche mit Hilfe von Transformer Modellen fokussiert haben.
Die meisten dieser Modelle funktionieren allerdings nur auf Englisch. Daher haben wir es uns zur Aufgabe gemacht, die Sucherfahrung für die deutsche Sprache massiv zu verbessern. Folglich werden zwei neue Modelle veröffentlicht, die die semantische Suche auch auf Deutsch auf die nächste Ebene befördern. Die beiden Modelle unterscheiden sich dabei in ihrer Präzision und dem Bedarf an Ressourcen.
Wie im Beispiel zu sehen ist, versteht die semantische Suche den Unterschied zwischen „dax steigt“ und „dax sinkt“ und zeigt nur die entsprechend relevanten Artikel auf, während die Standardmethode (BM25) den Kontext unserer Frage nicht versteht und die Dokumente anhand der auftretenden Worte und deren Häufigkeit ordnet.
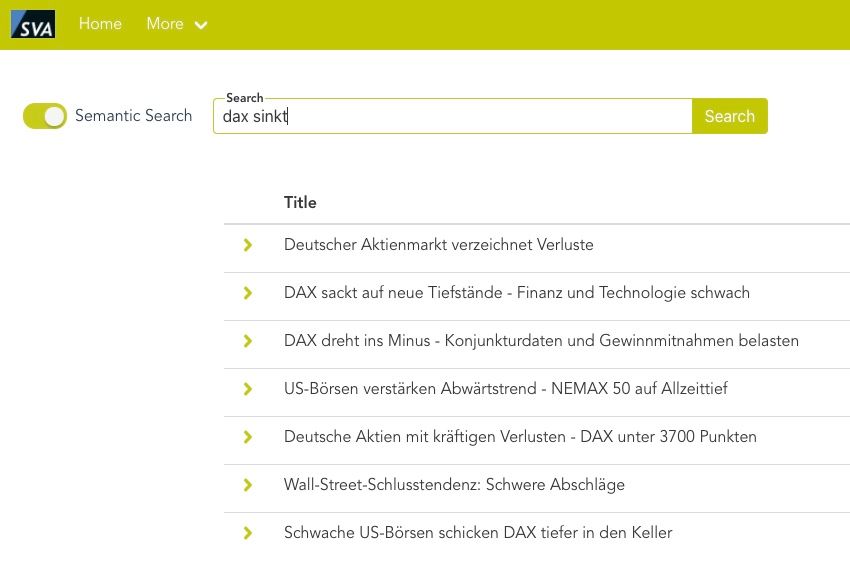
Abb.1: Ergebnis bei aktivierter Semantischer Suche zu Suchbegriff „dax sinkt“

Abb. 2: Ergebnis mit deaktivierter Semantischer Suche bei Suchbegriff „dax sinkt“
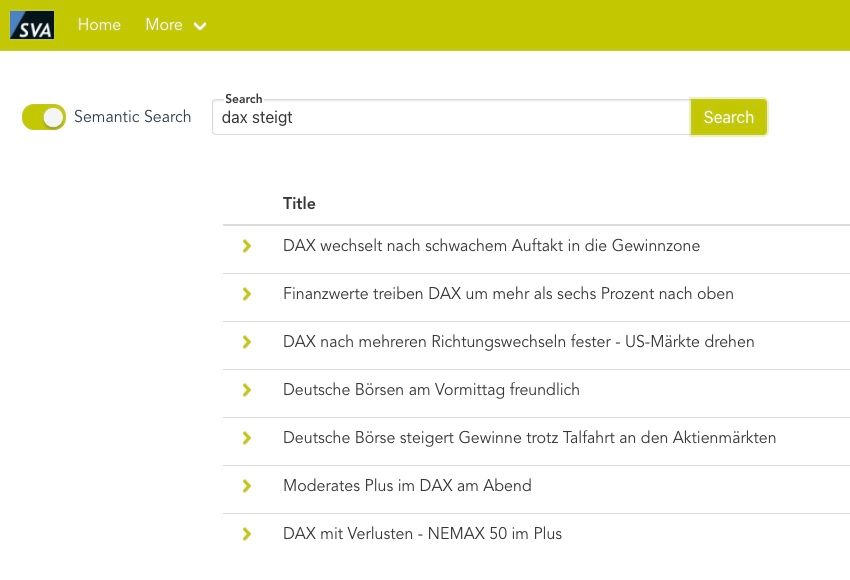
Abb. 3: Ergebnis mit aktivierter Semantischer Suche bei Suchbegriff „dax steigt“
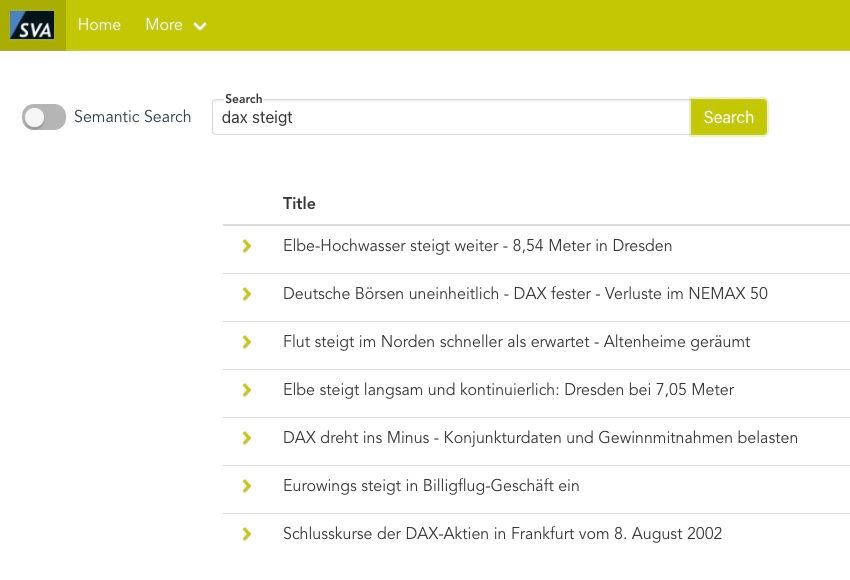
Abb. 4: Ergebnis bei deaktivierter Semantischer Suche bei Suchbegriff „dax steigt“
Die technischen Details
Die Modelle haben wir mit Hilfe des Frameworks SentenceBert (https://www.sbert.net/) auf einem maschinell übersetzten ms-marco Datensatz trainiert. Sie basieren dabei auf dem Electra Modell der german-nlp-group (https://huggingface.co/german-nlp-group/electra-base-german-uncased), da dieses das momentan stärkste Modell auf Deutsch ist, bei dem die Groß- und Kleinschreibung keine Rolle mehr spielt.
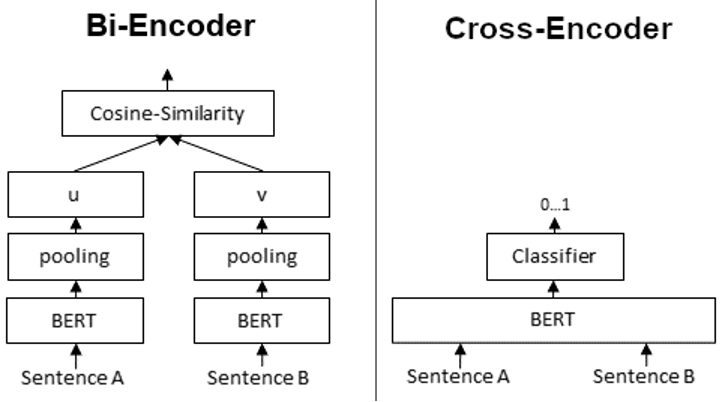
Abb. 5: Quelle/Referenz:https://www.sbert.net/examples/applications/cross-encoder/README.html
Das erste Modell: Ein Bi-Encoder
Dieses erstellt aus den Textdokumenten und der Frage einen sog. Kontext-Vektor, der mit Hilfe des Cosinus-Ähnlichkeitsmaßes die Möglichkeit bietet, schnell die Gesamtheit aller Dokumente mit der Frage abzugleichen. Dies ist bereits sehr leicht mit Produkten wie Elasticsearch umzusetzen.
Das zweite Modell: Ein Cross-Encoder
Es unterscheidet sich vom Bi-Encoder darin, dass es anstelle von Kontext-Vektoren einen Relevanz-Score aus der gemeinsamen Eingabe von Frage und Textdokument erstellt.
Dieses Verfahren ist deutlich rechenintensiver, bietet dafür aber eine höhere Präzision und damit relevantere Suchergebnisse.
Die besten Ergebnisse liefern die beiden Modelle jedoch gemeinsam. In unserer Demo dient der Bi-Encoder als „Vorab-Filter“. Dessen Top 100 Ergebnisse werden dann in den Cross-Encoder gegeben, um die Dokumente mit mehr Präzision neu zu sortieren.
Benchmarks geben Aufschluss
Zur Evaluation des Modells wurde das Benchmark-Framework BEIR (https://github.com/UKPLab/beir) in Kombination mit dem Testdatensatz GermanDPR von Deepset (https://deepset.ai/germanquad) verwendet und mit dem Standardverfahren für Textsuche BM25 verglichen.
Der GermanDPR Testdatensatz besteht aus 1025 Frage-Antwort-Paaren. Für jedes Paar gibt es einen richtigen Kontext, der Information beinhaltet bzw. der die Frage beantwortet und drei falsche Kontexte, denen die richtige Antwort fehlt. Das Suchverfahren ist also angehalten, basierend auf der Frage den positiven Kontext herauszusuchen. Für die Evaluation haben wir sowohl die positiven und negativen Kontexte in die Gesamtmenge der zu durchsuchenden Daten mit reingenommen und dedupliziert.
Für die bessere Übersichtlichkeit geht der Artikel nur auf eine Metrik ein – die Sensitivität (auch Richtig-Positiv-Rate). Die restlichen Metriken finden sich in den Links zu den Modellen.
Eine Sensitivität von 1 bedeutet, dass das Modell zu einer spezifischen Frage in 100% der Fälle den positiven Kontext aus der Gesamtmenge aller möglichen Antworten gefunden und die größte Relevanz zugeordnet hat. Die Antwort mit dem positiven Kontext würde in einem Suchfenster in 100% der Gesamtheit aller Fragen als erstes Ergebnis angezeigt werden.
Entsprechend bedeutet eine Sensitivität von 0, dass in keinem der Fälle die richtige Antwort als relevantestes Ergebnis an erster Stelle angezeigt wird.
Unsere Modelle wurden mit Hilfe von BEIR evaluiert, indem sie mit dem Standardverfahren BM25 (Elasticsearch) verglichen wurden. In der folgenden Tabelle sind die Sensitivitäten für die oben beschriebene Evaluierung auf Basis des GermanDPR Testdatensatzes aufgelistet.
| BM25 | Bi-Encoder | Cross-Encoder + BM25 (Top 100) | |
| Sensitivität (Recall@1) | 0.1463 | 0.4624 | 0.5980 |
Abb. 6: Benchmarkvergleich
Somit liefern die Modelle für diese Metrik mindestens eine dreifach bessere Performance und stützen damit die Überlegenheit von neuronalen Netzen gegenüber BM25 in dem Gebiet des “Information Retrieval” (übersetzt: “Informationsabfrage”).
Bi-Encoder: https://huggingface.co/svalabs/bi-electra-ms-marco-german-uncased
Cross-Encoder: https://huggingface.co/svalabs/cross-electra-ms-marco-german-uncased
Referenzen:
- Nils Reimers et al, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, https://arxiv.org/pdf/1908.10084.pdf
- Sebastian Hofstätter et al , Improving Efficient Neural Ranking Models with Cross-Architecture Knowledge Distillation , https://arxiv.org/abs/2010.02666
- Nandan Thakur et al, BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models, https://arxiv.org/abs/2104.08663
- Timo Möller, Julian Rischand, Malte Pietsch deepset GmbH ,GermanQuAD and GermanDPR: Improving Non-English Question Answering and Passage Retrieval, https://arxiv.org/abs/2104.12741
- Philip May, Philipp Reissel, https://huggingface.co/german-nlp-group/electra-base-german-uncased
- Microsoft AI & Research, https://microsoft.github.io/msmarco/
