Manuel Dorobek
Manuel Dorobek Schon 1996 schrieb die deutsche Philologin [Philologie ist die zusammenfassende Bezeichnung für die Sprach- und Literaturwissenschaft einer Sprache] und Politologin Heidrun Deborah Kämper über den Nachweis der Autorschaft in einem Fall über Ausgleichsansprüche. Unter anderem wurde der nicht nachweisbare Besitz eines Aktienpaketes behauptet. Die Antragstellerin fand während des langanhaltenden Verfahrens einen angeblichen Brief ihres Schwiegervaters aus dem Jahre 1948. Eine Textanalyse des Briefs und Vergleichsmaterials konnte beweisen, dass es sich bei diesem Brief um eine Fälschung handeln musste (Kämper, 1996). Bis heute wird der Rat von Expert:innen auf dem Gebiet der forensischen Linguistik herangezogen, um in Fällen zu ermitteln und eine Aussage darüber zu treffen, ob ein Text von einer bestimmten Person geschrieben wurde, oder um Profile der Autor:innen zu erstellen (Bauer, 2018).
Eine standardisierte Methode existiert bei der Erkennung von Autor:innen nicht (Dern, 2003). Expert:innen verwenden hierzu eine Reihe verschiedener Ansätze, welche auf der Untersuchung der Orthographie, Morphologie, der Syntax oder der Lexik basieren und diese qualitativ bewerten (ebd.). Neben diesen Verfahren existieren auch quantitative Ansätze, die durch statistische Methoden und das Definieren sprachlicher Merkmale versuchen, die Charakteristik bestimmter Autor:innen zu erfassen und dadurch deren individuellen Stil zu ermitteln (Bönninghoff, et al., 2019, S. 695). In der englischen Sprache existieren bereits einige automatisierte Verfahren unter diesem Ansatz wie Halvani, Steinebach, & Neitzel (2014), Abbasi & Chen (2008), Narayanan, et al. (2012), Potha & Stamatatos (2014) und: Stamatatos (2009).
In der deutschen Literatur existieren kaum Veröffentlichungen über ein Verfahren der automatisierten Autorschaftsanalyse. Aus diesem Grund beschäftigte ich mich im Rahmen meiner Masterthesis mit der Entwicklung eines solchen Modells für die deutsche Sprache und der Bewertung der verwendeten Sprachmerkmale an diesem Modell [Zur vollständigen Thesis].
Datengrundlage
Als Datengrundlage dienten Artikel der Seite „Musikreviews.de“, einem Magazin für Album-Kritiken, Nachrichten und Interviews aus den Genres Metal, Progressive und Rock. Der größte Vorteil dieser Artikel ist, dass deren Veröffentlichung ausschließlich den entsprechenden Redakteur:innen unterliegt. Es werden keinerlei Kürzungen oder andere Änderungen vorgenommen. Dies ist eine notwendige Grundlage für die Autorschaftsanalyse, weil nur so ein Text den jeweiligen Autor:innen zugewiesen werden kann. Mithilfe eines Webscrappers wurden für jeden der 25 Autor:innen 100 Artikel heruntergeladen. Die durchschnittliche Länge der Artikel beträgt 378,95 Wörter.
Klassifikation
Die Autor:innen eines Textes können als Kategorie oder Label bezeichnet werden. Der Algorithmus im supervised learning besitzt die Aufgabe Eingabedaten einer solchen Kategorie zuzuordnen (Bonaccorso, 2017, S. 10). Durch einen Supervisor wird eine präzise Messung des Fehlers zurückgegeben, welche direkt mit dem bekannten Ziel verglichen werden kann (ebd.). Mit dieser Information können die Parameter so angepasst werden, dass das Ausmaß der globalen Verlustfunktion minimal wird (ebd.). Jede Iteration präzisiert die Funktion. Die Optimierung der Funktion ermöglicht das spätere Bestimmen unbekannter Autor:innen.
Für die Klassifikation wurden drei verschiedene Klassifikatoren betrachtet: K-Nearest-Neighbor (KNN), Gaussian Naive Bayes (GNB) und Support Vector Machines (SVM). Aufgrund ihrer unpräzisen und schwankenden Ergebnisse in diesem Anwendungsfall wurden die Klassifikatoren KNN und GNB nicht weiter betrachtet. Im Gegensatz dazu konnte die treffliche Klassifikation mittels SVM bestätigt werden.
Eingabedaten
Als Eingabedaten wurden 15 verschiedene Merkmale näher betrachtet. Diese werden in der folgenden Tabelle aufgelistet. Einige Merkmale sind aufgrund ihrer Abhängigkeit vom Inhalt beziehungsweise Thema des Textes in der Autorschaftsattribution sehr umstritten. Der Unterscheidungswert dieser Merkmale steht in direktem Zusammenhang mit dem Grad der inhaltlichen Divergenz zwischen den Autor:innen und den Testsätzen. Das bedeutet, dass ein Ergebnis verfälscht werden kann, wenn ein Merkmal zu stark durch den Inhalt des Textes beeinträchtigt wird und dadurch der Schreibstil der Autor:innen nicht erkannt werden kann. Ein gutes Beispiel ist Bag-of-Words: Hier stehen genretypische Wörter im Konflikt mit solchen, die den Autor:innen zuzuordnen sind. In der folgenden Tabelle wurden Merkmale, bei denen von einer starken Abhängigkeit zum Thema auszugehen ist mit einem „x“ markiert.
| Merkmal | Beschreibung | T |
| Bag-of-Words | Anzahl der vorkommenden Wörter Beispiel (“Maus”, “Haus”) | x |
| Wort-N-Gramme | Beispiel: 2-Gramm „großes Haus“, 3-Gramm „mein großes Haus“ | x |
| Anzahl der Wörter | Anzahl der Wörter | x |
| Wortlänge | Frequenz von Wörtern mit 1–20 Buchstaben | |
| Yule’s K | Wortschatzreichtum, statistischer Messwert, der die Uniformität oder Diversität des Wortschatzes bestimmt | |
| Sonderzeichen | Anzahl Sonderzeichen (z.B., @#$%ˆ ) | |
| Zeichen-Affix-N-Gramme | Präfixe, Suffixe, Leerzeichen-Suffix, Leerzeichen-Präfix | |
| Zeichen-Wort-N-Gramme | Gesamt-Wort, Mittel-Wort, Multi-Wort | x |
| Zeichen-Interpunktion-N-Gramme | Anfangs-Interpunktion, Mittel-interpunktion, End-Interpunktion | |
| Ziffern | Ziffern (0-9) | |
| Funktionswörter | Artikel (der, das, einer, …), Konjunktionen (und, oder, …) | |
| Wortarten | Frequenz der Wortarten (e.g., Nomen, Adjektiv) | |
| Wortarten-N-Gramme | Beispiel: 2-Gramm „Nomen, Adjektiv“ | |
| Satz-Anfänge/-Endungen | Satzanfang (Nomen), Satzende (finites Verb), … | |
| Flesch Reading Ease Score | Formel oder ein Verfahren, welches versucht, die Lesbarkeit eines Textes formal zu bestimmen. |
Tabelle 1: Verwendete Merkmale
Einige der Merkmale besaßen eine Vielzahl von Ausprägungen, welche es vor der weiteren Verarbeitung zu verringern galt. Beispielsweise befanden sich in der Textsammlung von 2500 Artikeln ungefähr 400.000 verschiedene Wort-2-Gramme und 71.000 verschiedene Wörter. Neben dem Eliminieren von Merkmalsausprägungen mit einer sehr geringen oder sehr hohen Häufigkeit wurde sich für ein kombinierten Ansatz aus Filtern und Wrappern entschieden.
Datenvorbereitung
Weiterhin galt es in der Datenvorbereitung bestehende Korrelationen zwischen einzelnen Merkmalen aufzulösen und die bestmöglichen Varianten der Merkmale zu bestimmen. Beispiele für solche Varianten sind verschiedene Längen von N-Grammen oder das Bilden einer Intervallgrenze bei extrem langen Wörtern. So konnte die These bestätigt werden, dass die genaue Wortlänge bei Wörtern über 20 Zeichen weniger Informationen verspricht als die Tendenz der Autor:innen, sehr lange Wörter zu verwenden. Weiterhin ließ sich feststellen, dass lange Wortarten N-Gramme oder Wort-N-Gramme keinen Mehrwehrt für die durchgeführte Klassifikation bieten.
Die These, dass ein Entfernen der themenabhängigen Merkmale zu gleichbleibenden oder besseren Klassifikationsergebnissen führen kann, galt es im nächsten Schritt zu prüfen. Hierbei ist anzumerken, dass keine genaue Aussage darüber getroffen werden konnte, ob themenabhängige Unterschiede zwischen den Texten bestehen. Es besteht allerdings die Annahme, dass Musikreviews verschiedener Genres eine große Schnittmenge an themenspezifischem Vokabular besitzen. Eine Gegenüberstellung der Klassifikationsergebnisse unter der Verwendung aller Merkmale und der Bewertung ohne themenabhängige Merkmale führte zu dem Ergebnis, dass nahezu die gleichen oder teilweise bessere Ergebnisse unter Verwendung von rund 18,5% der Merkmalsausprägungen ermittelt werden können. Dies wird in der folgenden Abbildung dargestellt.
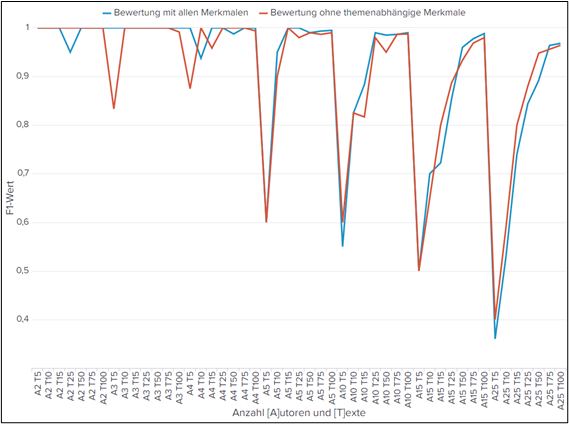
Abb. 1: Vergleich themenabhängige und themenunabhängige Merkmale
Ergebnisse
Die Klassifikationsergebnisse werden in Tabelle 2 zusammengefasst. Hierbei gilt es anzumerken, dass die Anzahl der Texte einer Anzahl vor einem Trainings-/Testsplitting entspricht. In der Arbeit wurde ein Splitting von 60:40 verwendet. Das bedeutet, dass die Klassifikationsergebnisse unter der Verwendung von 0.6*Textanzahl pro Autor:in erzielt werden konnte. Dies entspricht ähnlichen Ergebnissen wie den für die englische Sprache entwickelten Modellen, wodurch die Frage nach einer möglichen Klassifikation in der deutschen Sprache mit „Ja“ beantwortet werden kann. Allerdings muss bei dieser Aussage beachtet werden, dass in dieser Arbeit einige Voraussetzungen getroffen wurden. Darunter fallen zum Beispiel eine ausreichende Textlänge und dem Ausschluss eines bewussten Verfälschens des Schreibstils.
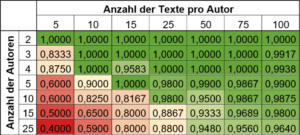
Tabelle 2: Klassifikationsprobleme
Fazit
Zusammenfassend lässt sich die zugrunde liegende Fragestellung damit beantworten, dass das Unterscheiden von Autoren mithilfe von sprachlichen Merkmalen der existierenden Forschung in der deutschen Sprache möglich ist. Die Bewertung der genannten Merkmale wurde hierbei größtenteils bestätigt. Dennoch konnten diese Ergebnisse nur unter dem Ausschluss einiger Herausforderungen erzielt werden. Dabei erfolgte die Auswertung lediglich auf der Grundlage eines Datensatzes. Folglich können die Erkenntnisse dieser Arbeit als Grundlage für eine weitere Forschung betrachtet werden.
Literaturverzeichnis
Abbasi, A., & Chen, H.-c. (März 2008). Writeprints: A Stylometric Approach to Identity-level Identification and Similarity Detection in Cyberspace. ACM Transactions on Information Systems(26), S. 1-29. doi:10.1145/1344411.1344413
Bauer, R. (6. September 2018). Sie erforscht die Sprache des Bösen: So überführt Gudrun Müller Täter anhand ihrer Worte. Abgerufen am 20. Dezember 2020 von Focus: https://www.focus.de/wissen/forensische-linguistik-gudrun-mueller-ueberfuehrt-taeter-anhand-ihrer-worte_id_9495954.html
Bonaccorso, G. (2017). Machine Learning Algorithms. Birmingham: Published by Packt Publishing Ltd.
Bönninghoff, B., Hessler, S., Kolossa, D., Kucharczik, K., Nickel, R., & Pittner, K. (11. November 2019). Autorschaftsanalyse Verstellungsstrategien und Möglichkeiten der automatisierten Erkennung. Datenschutz und Datensicherheit – DuD, 43, S. 691–699.
Dern, C. (2003). Sprachwissenschaft und Kriminalistik: zur Praxis der Autorenerkennung. (D. Gruyter, Hrsg.) Zeitschrift für germanistische Linguistik(31), S. 44-77.
Feiguina, O., & Hirst, G. (2007). Authorship Attribution for Small Texts: Literary and Forensic Experiments. Proceedings of the SIGIR 2007 International Workshop on Plagiarism Analysis, Authorship Identification, and Near-Duplicate Detection, PAN 2007. Amsterdam.
Halvani, O., Steinebach, M., & Neitzel, S. (2014). Lässt sich der Schreibstil verfälschen um die eigene Anonymität in Textdokumenten zu schützen? (S. 229-241). Bonn: Gesellschaft für Informatik e.V.
Kämper, H. (1996). Nachweis der Autorenschaft. Kriminalistik, 50(8-9), S. 561-566.
Liu, Y. H. (2019). Python Machine Learning By Example (2 Ausg.). Birmingham: Packt Publishing Ltd.
Narayanan, A., Paskov, H., Gong, N. Z., Bethencourt, J., Stefanov, E., Shin, E., & Song, D. (2012). On the Feasibility of Internet-Scale Author Identification. 2012 IEEE Symposium on Security and Privacy (S. 300-314). San Francisco: IEEE. doi:10.1109/SP.2012.46
Potha, N., & Stamatatos, E. (2014). A Profile-Based Method for Authorship Verification. Hellenic Conference on Artificial Intelligence, (S. 313-326). Karlovassi. doi:10.1007/978-3-319-07064-3_25
Stamatatos, E. (16. Dezember 2009). A survey of modern authorship attribution methods. Journal of the American Society for Information Science and Technology, 60(3), S. 538-556. doi:10.1002/asi.21001