

Haben Sie schon mal Daten aus verschiedenen Quellen mühsam zusammengetragen, um wertvolle Erkenntnisse zu gewinnen? Oder mit Ihrer Infrastruktur und einem sehr langsamen Dashboard gekämpft, das ständig abstürzt? Das muss so nicht bleiben. Wozu kämpfen? Die moderne Welt liegt in der Cloud. Die Kernaussage hierbei ist, innovative Ideen zu verwirklichen, anstatt unnötigen Aufwand erzeugen.
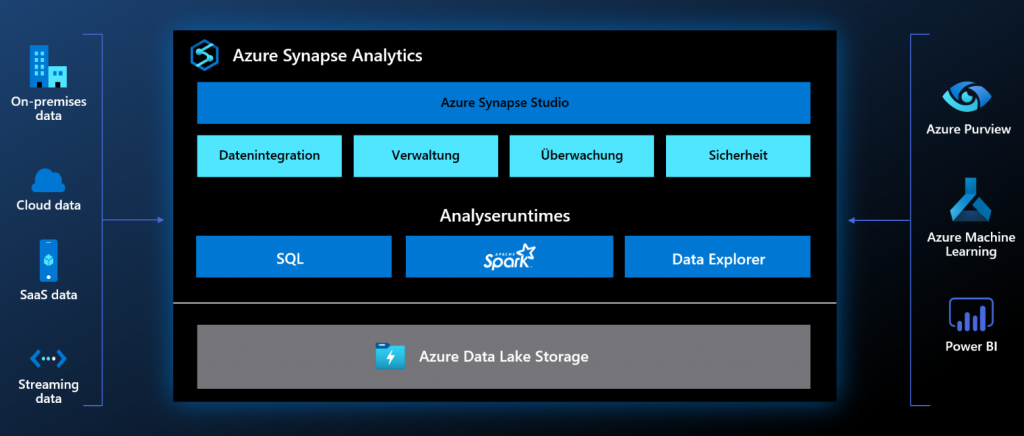
Azure Synapse – cloudbasierte PaaS-Lösung
Cloudbasierte „Plattform as a Service“ (PaaS)-Lösungen geben Ihnen und Ihrem IT-Team die Möglichkeit, die Zeit, die Sie für die Konfiguration der Infrastruktur aufwenden würden, unmittelbar in das Projekt selbst zu investieren. Daraus resultiert eine effizientere Kapazitätsnutzung des eigenen IT-Teams sowie die Nutzung einer Infrastruktur, die stets up-to-date ist und entsprechend den höchsten Sicherheitsstand bietet. In diesem Beitrag soll eine solche cloudbasierte PaaS-Lösung – Azure Synapse Analytics – von Gartner Magic Quadrant-Leader Microsoft vorgestellt werden. Azure Synapse ist Microsofts Analytics-Plattform in der Cloud, welche Enterprise Data Warehousing, Datenintegration und Big Data-Analysen in einer einzigen verwalteten Umgebung kombiniert. Der integrierte Unternehmensanalysedienst ist in der Lage, riesige Datenmengen gleichzeitig zu verarbeiten, sodass daraus schneller und verlässlicher fundierte Erkenntnisse gewonnen werden können.
Warum Azure Synapse?
Warum braucht man überhaupt Azure Synapse? Wie bereits erwähnt wurde, vereint Azure Synapse die jeweils beste Technologie aus verschiedenen Bereichen: SQL-Technologie für Data Warehousing, Spark-Technologie für Big Data-Analysen, Azure Data Factory für die Datenintegration & Pipelines, Data Explorer für die Analyse von Protokollen und Zeitreihen. Darüber hinaus besteht eine sehr gute Integration in andere Azure-Dienste, z. B. Power BI, Azure Purview, Cosmos DB oder Azure ML. Anstatt mit dutzenden einzelnen Tools zu jonglieren, stehen alle notwendigen Dienste direkt auf der Synapse-Plattform zur Verfügung. Da es eine PaaS-Lösung ist, kümmert sich der Plattform-Anbieter Microsoft um die Verfügbarkeit der Infrastruktur, die zu 99,9 % garantiert ist. Dazu kommen weitere Vorteile: einfache Skalierbarkeit gemäß den individuellen Workload-Anforderungen, Kosteneffizienz dank des Konzepts „Pay-as-you-go“ (eine nutzungsbasierte Bezahlung) sowie Agilität und Flexibilität. Dies sind optimale Rahmenbedingungen, um bspw. den lange geplanten „Proof of Concept“ (PoC) endlich anzugehen. Sobald die Rahmenbedingungen und Zielsysteme identifiziert sind, können außerdem Reservierungspläne für eine Kostenoptimierung genutzt werden.
Außer der allgemeinen Vorteile, die fast jede cloudbasierte Lösung anbietet, liefert Azure Synapse einige grundlegende Funktionalitäten, die vor allem im Big Data-Kontext relevant sein können:
- Gleichzeitige Ausführung von bis zu 128 Abfragen mit Massively Parallel Processing (MPP)
- Eine zentrale Benutzeroberfläche – Synapse Studio – für die Erstellung von Lösungen sowie für Verwaltungs- und Security-Funktionen
- Kostengünstige Speicherkapazität und Transaktionen mithilfe von Azure DataLake
- Verbindung zu verschiedenen Datenquellen, unabhängig davon, ob sich diese im Rechenzentrum oder in der Cloud befinden
- Kompatibilität zu europäischen Datenschutzgesetzen
- Die Möglichkeit, Datenbanken temporär zu stoppen und innerhalb weniger Minuten fortzusetzen
Vom Modern Data Warehouse bis zum Real-Time Analytics
Der Clouddienst steht bereit, um loszulegen. Doch jetzt stellen sich die nächsten Fragen: “Wie starte ich ein Analytics-Projekt? Welche Analysen will ich durchführen und welche Schritte sind dafür notwendig?”
Unabhängig von Ihrem Analyseziel ist es meist unerlässlich zunächst ein Modern DWH aufzubauen. Transaktionale OLTP-Datenbanken, welche die technische Basis für operative Arbeitsvorgänge bilden, sind in der Regel nur darauf ausgelegt, Daten zu schreiben sowie in geringerem Umfang zu lesen. Für ein effizientes Reporting wiederum sind sowohl aktuelle als auch historische Daten in größeren Mengen gefordert. Unter diesen Voraussetzungen bietet das Modern DWH den Vorteil, dem Endanwender eine einheitliche und qualitativ hochwertige Datengrundlage bereitzustellen und somit auch Schatten-IT-Lösungen vorzubeugen.
Wie unterscheidet sich ein Modern Datawarehouse vom traditionellen Datawarehouse?
Der wesentliche Unterschied liegt in dem Ansatz der Cloudnutzung begründet. Als “Modern” wird nicht exklusiv die technologische Umsetzung gesehen, sondern auch die Möglichkeit ein Datawarehouse modern aufzubauen.
Nun stellt sich die Frage: ”Was bedeutet es im Wesentlichen ein Datawarehouse modern aufzubauen?”
- Verwendung von unabhängigen, skalierbaren Infrastrukturressourcen der PaaS-Landschaft statt dem Aufbau einer eigenen Infrastruktur oder Private Cloud
- Konsolidierung und Demokratisierung von Daten durch Speicherung von strukturierten semi- oder unstrukturierten Datentypen im DataLake
- Bedarfsgerechte Nutzung der plattformbasierten Services je nach Analyseschicht und –ziel
Ein kurzer Blick in die praktische Umsetzung verdeutlicht diesen Ansatz. Dies soll am Beispiel eines Demo-Use Cases dargelegt werden:
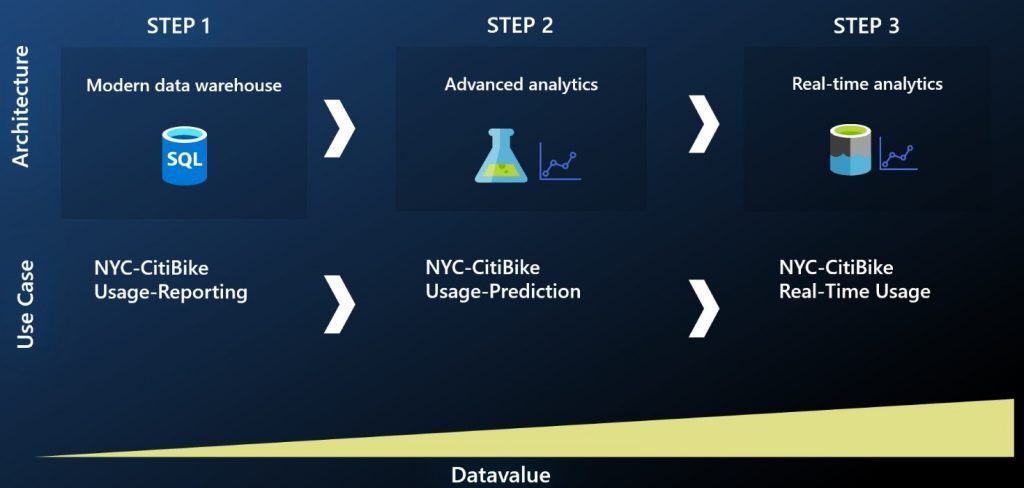
Step 1 – Modern Datawarehouse
Harmonisierung unterschiedlicher Datenquellen in einem Datawarehouse sowie Modellierung und Visualisierung
Step 2 – Advanced Analytics
Aufbau von Machine-Learning-Modellen für weitreichendere Erkenntnisse und damit einen Blick in die Zukunft
Step 3 – Real-Time Analytics
Echtzeitanalyse von Daten, um auf dieser Grundlage auf zeitkritische Ereignisse in Geschäftsprozessen reagieren zu können
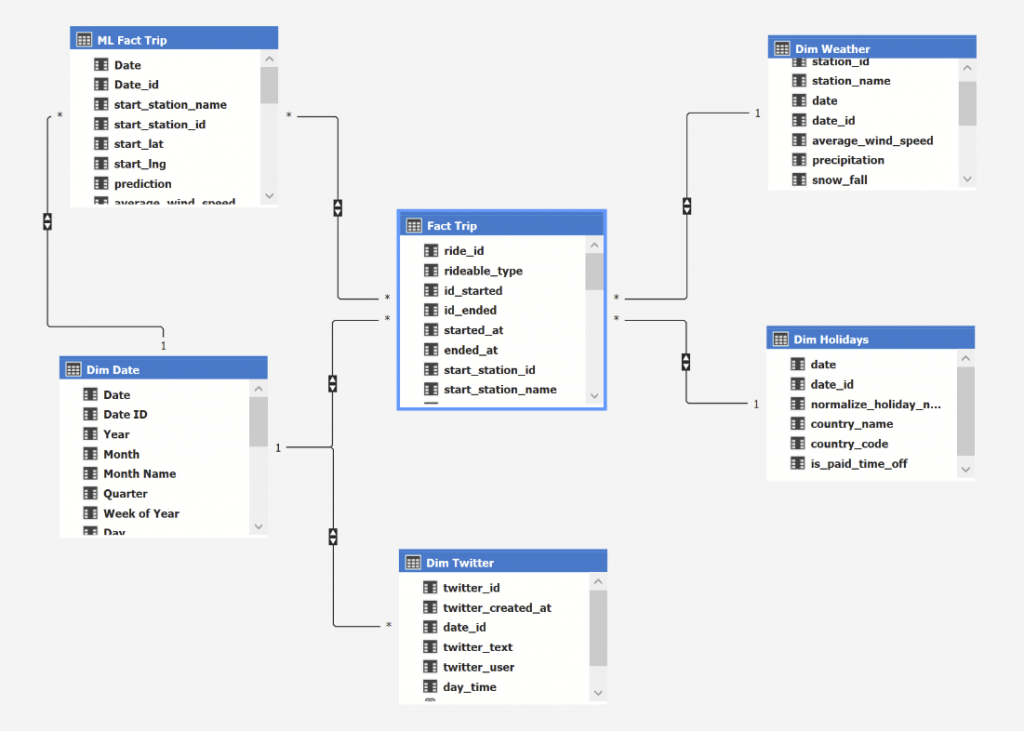
Citi Bike Use-Case
Diese Demo wurde auf Basis von Citi Bike-Daten aufgebaut. Diese sind öffentlich zu Analysezwecken verfügbar. Das Unternehmen Citi Bike betreibt das größte Fahrrad-Share-System in New York und ist zu einem wesentlichen Bestandteil des städtischen Verkehrsnetzes geworden. Der Datensatz enthält über 100 Millionen Fahrrad-Fahrten von 2015 bis 2021. Citi Bike verfügt mittlerweile über 1000 Fahrrad-Stationen und hat zurzeit mehr als 17.000 Fahrräder in New York zur Verfügung.
Es handelt sich um eine große Menge an Daten, welche früher eine große Herausforderung für jede BI-Landschaft darstellte – insbesondere im Hinblick auf Verarbeitung, Analyse und Visualisierung. Heute hingegen ist dies dank der Cloud-Technologie kein Problem!

Abb. 3: Übersicht der Datenquantität von Citi Bike Daten
Haben Sie eine ideale BI-Architektur zur Datenverarbeitung, von der Extraktion bis zur Visualisierung, konzipiert? Dann besteht der nächste Schritt darin, aus der Vielzahl an verschiedenen Azure-Diensten die jeweils am besten geeigneten auszuwählen.
Für diesen Use Case wurde eine BI-Lösung ausgearbeitet, welche in die meisten unternehmerischen Prozesse integriert werden kann. Üblicherweise verfügen Unternehmen über mehrere Quellsysteme, aus denen die Daten automatisiert extrahiert werden müssen. Die erste Komponente der Architektur ist ein Data Lake. Hierbei handelt es sich um einen großen Speichertopf, in dem Roh-Daten in allen möglichen Datenformaten und -strukturen gespeichert werden können. Die Citi Bike-Daten liegen in einem S3-Bucket der AWS Cloud. Die Wetter- & Twitter-Daten wurden über API abgerufen.
| Quellsystem | Datentyp |
| S3 Bucket | CSV |
| Wetter API | JSON |
| Twitter API | JSON |
Datenverarbeitungsstrecke mit Azure Synapse
Die Daten aus dem Data Lake können mehreren Usern zu jeweils verschiedenen Verarbeitungszwecken zur Verfügung gestellt werden. Da die Quellsysteme Daten nicht immer in der wünschenswerten Qualität liefern, können PySpark oder SQL genutzt werden, um die Datenstrukturen anzupassen. In diesem Beispiel ist PySpark die zweite Komponente der Architektur. Die fehlerhaften Datenformatierungen und unstrukturierten Daten wurden mit PySpark in einem spaltenorientierten Apache Parquet-Format konsolidiert, da es für eine Verarbeitung sowie Speicherung großer Datenmengen optimiert ist. Durch das spaltenbasierte Format werden die Daten zudem effizienter komprimiert, sodass weniger Speicherplatz verbraucht wird.
Nachdem die transformierten Daten nun im Parquet-Format vorliegen, können sie in einer Azure SQL-Datenbank oder einem dedizierten SQL-Pool persistiert werden. Die persistierten Daten dienen als Grundlage für unser Reporting. Allerdings müssen diese erst modelliert werden. Die Modellierung kann mit Hilfe von Analysis Services durchgeführt werden. Diese Komponente ist optional, bringt aber einen klaren Performancevorteil in der Kombination mit Power BI.
Wenn das Parquet-Format so effizient ist, stellt sich die Frage: “Warum braucht man überhaupt noch eine SQL-Engine und Analysis Services?” Sobald große Datenmengen visualisiert werden müssen, ist es notwendig, eine skalierbare Engine zu haben, die in der Lage ist, diese Daten zu verarbeiten. Ein Data Lake ist eher eine Zwischenschicht, auf der man die Daten aus den verschiedenen Quellen speichert. Die komplexe Datenverarbeitung, Modellierung und direkte Verbindung mit einem BI-Tool ist hingegen nicht im Data-Lake-Kontext angedacht. Es ist zwar möglich, allerdings sind andere Services besser dafür geeignet.
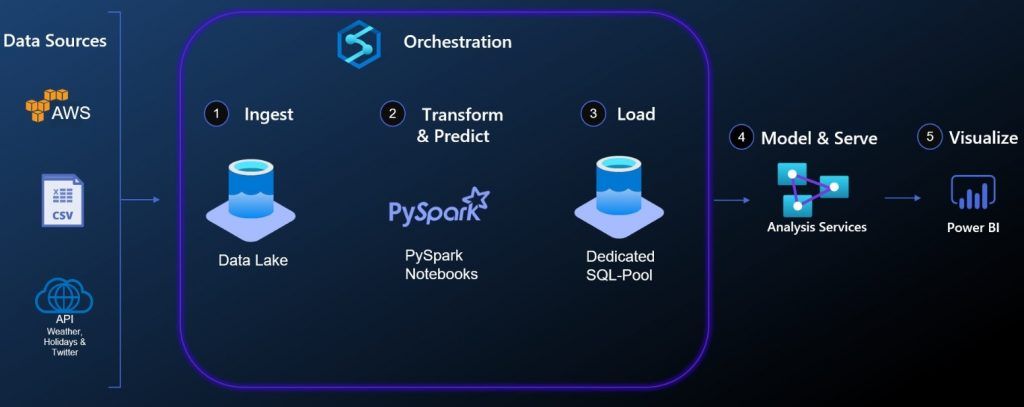
Analysis Services & Visualisierung in Power BI
Azure Analysis Services ist ein weiterer PaaS-Service in der Azure Cloud, welcher es ermöglicht, eine semantische Modellierung der Daten abzubilden und daraus resultierende Datenmodelle bereitzustellen. Die Datenmodelle werden im RAM vorgehalten und ermöglichen so sehr schnelle Zugriffszeiten. Außerdem bietet Analysis Services in Verbindung mit Power BI den Vorteil einer nativen Konnektivität. Abfragen aus Power BI müssen nicht erst verarbeitet bzw. übersetzt werden, da die gleichen Metadaten-Objekte und Strukturen genutzt werden. Als Ergebnis wird dadurch ein zusätzlicher positiver Effekt auf die Reaktionszeit der Power BI-Berichte erzielt.
Nun kommen wir zum spannendsten Teil: Das Datenmodell kann direkt an Power BI angebunden und ermöglicht somit die Nutzung der dort zur Verfügung stehenden, umfangreichen Visualisierungsmöglichkeiten. Das Tool ist sehr intuitiv und ermöglicht einen einfachen Einstieg in die Erstellung von interaktiven Reports und Dashboards.
Mithilfe von Power BI haben wir einen solchen interaktiven Bericht erstellt, in dem die wichtigsten Grundzahlen, Korrelationen sowie Analysen der Daten visuell dargestellt werden.
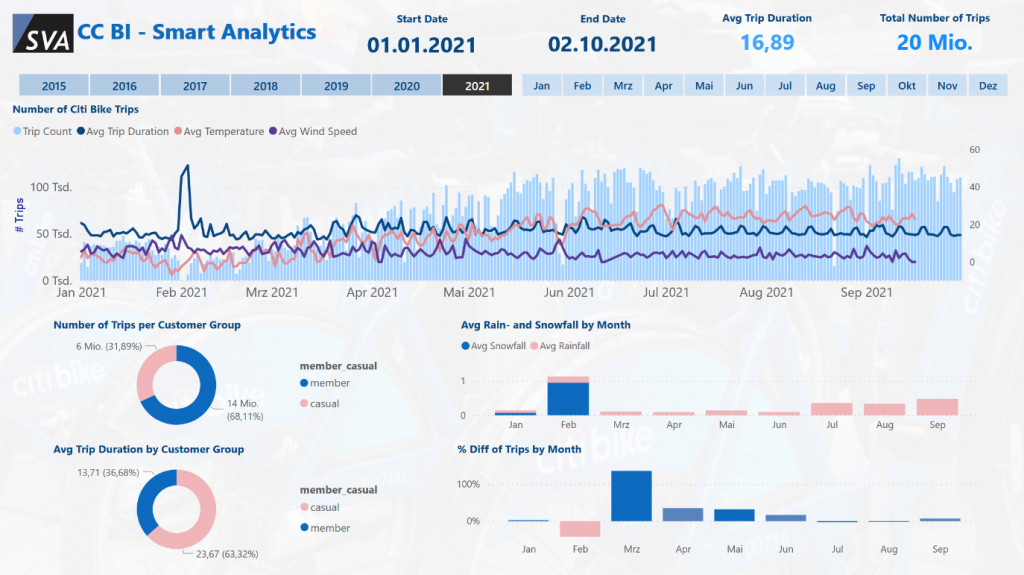
Über 80% der Geschäftsdaten enthalten einen Standortkontext. Microsoft bietet eine Sammlung von Geodiensten und SDKs (Software Development Kits) wie Azure Maps an, welche es Ihnen ermöglichen Geodaten zu visualisieren. Auch in Power BI ist eine vorgefertigte Azure Maps-Lösung integriert, welche für die meisten Standardanalysen von Geodaten ausreichend ist. Um die Lokationen der Fahrradstationen darzustellen, eignet sie sich hervorragend!
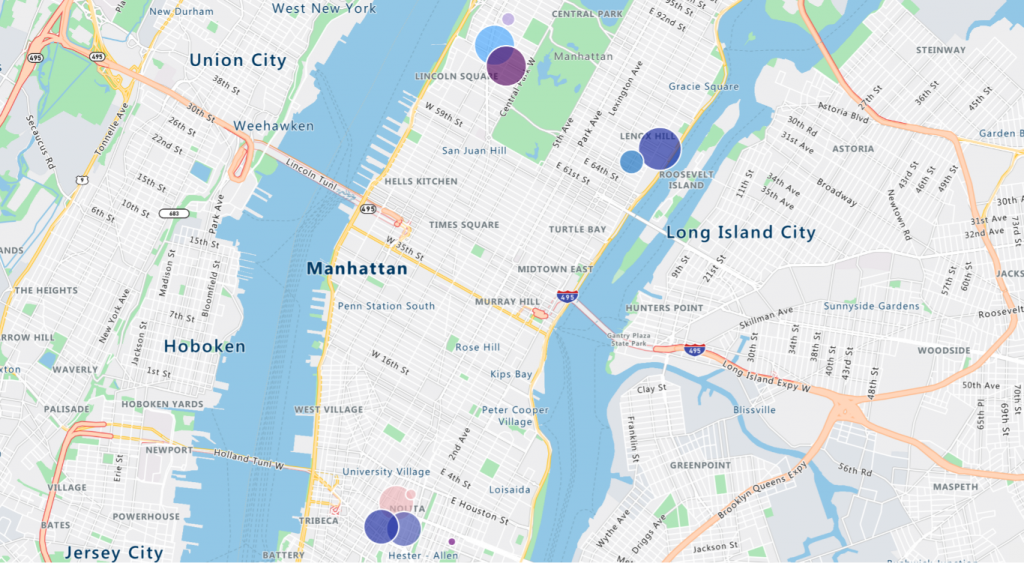
Je nach Kartenansicht ist außerdem ein unterschiedlicher Detaillierungsgrad möglich. So können zum Beispiel mit der Satelliten-Ansicht mehr Informationen über die einzelnen Stationen gesammelt werden. In der Abbildung kann man nicht nur die Fahrräder einer Station erkennen, sondern auch die Straßenseite, auf der sich diese befinden. Da nicht alle in den Daten vorhandenen Geo-Lokationen auch tatsächlich auf eine Station hinweisen, ist die Satelliten-Ansicht ziemlich hilfreich, um herauszufinden, wo sich tatsächlich eine Station befindet.

Ist Cloud zu teuer?
„Alles, was nur Geld kostet, ist billig“ sagt der US-amerikanische Autor John Steinbeck. Die Cloud ist nicht die günstigste Lösung auf dem Markt, allerdings kann angeführt werden, dass bei einem pragmatischen und gezielten Umgang mit den angebotenen Services, alle anfallenden Ausgaben begrenzt werden können. Kosteneffizient sind meist nur die Services, die auch wirklich verwendet werden. Nicht zu vergessen ist dabei, dass einige davon (z.B. SQL-Datenbanken oder virtuelle Maschinen) außerhalb der Arbeitszeit abgeschaltet werden können. Das Pay-As-You-Need-Modell kann Ihnen sogar helfen, die Kosten für Big Data-Projekte zu optimieren.
Ausblick
In diesem Blog wurde ein kleiner Einblick in Synapse Analytics gegeben: Eine PaaS-Lösung, die auch für viele Big-Data-Projekte interessant sein kann. Wie schon oben in der Abb. 2 demonstriert, steigt der Wert von Daten mit zunehmender Analysekomplexität. Dieser Blogartikel beschäftigt sich mit der technischen Umsetzung des ersten Schrittes und dient als Grundlage für weitere Analysen, z.B. mit Machine Learning. Dieser zweite Schritt ist für eine bessere Veranschaulichung als Video https://www.youtube.com/watch?v=9G9KYOUxHp0 dargestellt worden. Als Erweiterung des Use-Cases folgt im dritten Schritt Stream-Analytics.
Quellen:
https://docs.microsoft.com/de-de/azure/synapse-analytics/overview-what-is
https://msinfoworld.com/wp-content/uploads/2021/01/Cloud-Analytics-mit-Microsoft-Azure.pdf
https://beruhmte-zitate.de/zitate/133667-august-lammle-alles-reprasentative-kostet-geld/
https://docs.microsoft.com/de-de/azure/azure-maps/about-azure-maps#power-bi-visual
The Modern Data Warehouse in Azure: Building with Speed and Agility on Microsoft’s Cloud Platform, Matt How