
In der heutigen IT fällt mir immer wieder auf, dass Softwarepraktiken und System Engineering eng miteinander verbunden sind. Diese enge Verbundenheit spiegelt sich in der DevOps-Bewegung wider. Beispielsweise können Clean-Code-Prinzipien aus der Softwareentwicklung mithilfe der richtigen Systemauswahl und Integration in der Code Supply Chain automatisiert implementiert werden. Auf diese Weise werden sie durch Methodiken aus dem System Engineering nahtlos in Unternehmensprozesse integriert. Gleichzeitig wird Code nicht nur innerhalb der Softwareentwicklungsabteilung produziert, integriert und gewartet, sondern hat auch außerhalb dieser Bereiche erhebliche Relevanz für wertschöpfende Prozesse innerhalb der IT. Daher präsentiere ich die Clean-Code-Prinzipien als bedeutende Methode, die die gesamte Anwendungs-nahe und System-nahe Codeentwicklung beeinflusst. Um die Regeln des Clean Codes besser verstehen zu können, betrachten wir eine konkrete User Story im Kontext von Entscheidungsbäumen zur Auswahl eines verteilten Datenbanksystems.
Die in der Lösung der User Story erläuterten Refactoring-Vorschläge zielen darauf ab, die Wartbarkeit, Lesbarkeit und Integrationsfähigkeit des Codes zu verbessern. Mein Ziel ist es, dazu zu ermutigen, technische Schulden in Code-Segmenten jeder Art bewusst abzubauen, um die Qualität der Software weiter zu steigern.
Die User Story
Da viele Unternehmensprozesse einem stetigen Wandel unterliegen, bietet es sich an, Prozesse zu visualisieren, statt diese nur flach zu beschreiben. Idealerweise werden die Anwender:innen interaktiv durch den vorgegebenen Entscheidungsprozess geführt. Auf diese Weise werden die Auswirkungen der Entscheidungen auf den ersten Blick erkennbar gemacht.
Zur Auswahl einer geeigneten Datenbank zeigt die dargestellte Visualisierung klare Entscheidungskriterien, die berücksichtigt werden müssen. Insbesondere in verteilten Systemen besagt das CAP-Theorem, dass eine unvermeidliche Entscheidung zwischen unmittelbarer Verfügbarkeit der benötigten Daten (AP) und strenger Konsistenz in den Werten der gelieferten Daten (CP) getroffen werden muss. Das heißt wer eine verteilte Datenbank wählt, muss sich entscheiden, ob neu geschriebene Daten zuerst auf allen Maschinen synchronisiert werden und dann gelesen werden können (CP) oder mit etwaigen Inkonsistenzen sofort gelesen werden (AP).
Um die Auswirkungen dieser Entscheidung oder anderer Entscheidungen transparent zu machen, können Entscheidungsbäume herangezogen werden, die den gesamten Entscheidungsprozess zwischen Systemkomponenten anhand von bereits definierten Kriterien abbilden. Der Entscheidungsbaum wird in diesem Fall durch eine Komponente im JavaScript Framework Svelte abgebildet.
Die zentrale Herausforderung bei der Entwicklung ist es, die Darstellung der verschiedenen Hierarchieebenen des Entscheidungsbaumes dynamisch sichtbar zu machen. Sie beanspruchen ihren Platz auf der Webseite aufgrund der individuellen Nutzerinteraktion.
Einführung in das Svelte JavaScript Framework
Svelte bietet Vorteile im interaktiven Zusammenspiel der Nutzereingabe und der unmittelbaren Anpassung des Entscheidungsbaumes. Als ein modernes JavaScript-Framework konzentriert es sich auf die Entwicklung von Benutzeroberflächen. Das Framework setzt hier das Konzept der Reaktivität um. Damit werden Teile der Benutzeroberfläche automatisch aktualisiert, wenn sich beispielsweise der Username ändert.
Im Gegensatz zu anderen Frameworks wie React, Angular oder Vue wird der Code bei Svelte nicht zur Laufzeit interpretiert, sondern bereits vorab während des Build-Prozesses in effizienten Vanilla JavaScript-Code umgewandelt. Dies führt zu einer besseren Performance auf der Client-Seite. (Quelle: https://svelte.dev/)
Ein Svelte Projekt aufsetzen mit SvelteKit:
```bash
npm create svelte@latest myapp
cd myapp
## Developing
Once you've created a project and installed dependencies with `npm install`, start a development server:
npm run dev
```bashEine Beispielkomponente in Svelte, die standardmäßig JavaScript, HTML und CSS enthält:
```svelte
<script>
let user = 'Lisa@SVA';
</script>
<h1>Hallo, {user.toUpperCase()}!</h1>
<style>
h1 {
color: blue;
}
</style>
```
Clean-Code-Prinzipien nach Robert C. Martin
In seinen über 50 Jahren Erfahrung in der Softwareentwicklung hat Robert C. Martin maßgeblich am agilen Manifest mitgewirkt und die Grundprinzipien für agile Softwareentwicklung mitdefiniert (Quelle: https://agilemanifesto.org/principles.html). Er erklärt in seinem Standardwerk “Clean Code: A Handbook of Agile Software Craftsmanship” die Grundprinzipien von Clean Code, welche im Folgenden erläutert werden.
Grundprinzipien von Clean Code
Aussagekräftige und einheitliche Namen:
Variablen, Funktionen, Klassen und andere Code-Elemente sollten klar, aussagekräftig und zweckbeschreibend benannt werden. Der Code sollte leicht zu verstehen sein, auch ohne ausführliche Kommentare. Halte dich an eine einheitliche Namenskonvention. Konsistente Namen erleichtern das Verständnis des Codes.
Folgendes Beispiel wurde in der Entscheidungsbaumkomponente verwendet:
let treeLevel = [];
let allLabels = [];
let uniqueLabels = [];- treeLevel stellt den ausgewählten Teil des Entscheidungsbaumes dar, welcher durch die Selektion der Anwender:innen gerendert werden muss.
- allLabels steht für alle Entscheidungskriterien in der jeweiligen Entscheidungsebene, z.B. beim CAP-Theorem [CP, CP, P, AP]. Diese Variable wird benötigt, um die Button-Gruppe darzustellen, die visuell durch gleiche Farben anzeigt, wie viele Systeme durch ein Entscheidungskriterium abgebildet werden.
- uniqueLabels werden benötigt, um das Entscheidungskriterium durch den Auswahlpfeil darzustellen. Diese repräsentieren nur die eindeutigen Entscheidungskriterien, in diesem Falle beispielsweise [CP, P, AP].
Klassen und Funktionen kurz und prägnant halten:
Funktionen erfüllen idealerweise nur eine abgegrenzte Aufgabe und besitzen eine klare Verantwortlichkeit. Dadurch ist der Code einfacher zu verstehen und Änderungen sind weniger fehleranfällig. Wenn eine Funktion zu lang wird, sollte überlegt werden, ob sie in kleinere Funktionen aufgeteilt werden kann.
Vermeidung von Seiteneffekten:
Funktionen sollten vorhersagbar sein und keine unerwarteten Seiteneffekte haben. Das bedeutet, dass eine Funktion bei gleichen Eingaben immer das gleiche Ergebnis liefert.
Code duplication vermeiden (Dry-Prinzip):
Doppelter Code sollte vermieden werden, indem gemeinsame Funktionalitäten in Funktionen oder Klassen extrahiert werden. Dies verhindert Inkonsistenzen und erleichtert die Wartung, da Code nur an einer Stelle geändert werden muss.
Folgendes Beispiel zeigt eine Codeduplikation, in der die Anzahl der Hierarchieebenen des Baumes (treeLevel) durch die HTML-Blöcke bereits vorher statisch vorgegeben wurden und somit nicht dynamisch auf alle Entscheidungsbäume flexibler Tiefe reagieren können. Durch die Abstraktion der HTML-Blöcke als einen einzelnen Block, der nur ein treeLevelObjekt konsumiert, kann die unnötige Wiederholung hier vermieden werden.
{#if treeLevel1.length > 0}
<div class="container Level{levels[1]}">
<div class="row">
{#each treeLevel1
.filter((x) => Object.values(x)[0].length > 1)
.map((x) => Object.keys(Object.values(x)[0][1])[0])
.filter((item, i, ar) => ar.indexOf(item) === i) as col, j}
<div class="col">
<div class="row justify-content-sm-center">
<div class="col">
<button class="btn btn-light btn-circle btn-xl">{col}</button>
...
{#if treeLevel2.length > 0}
<div class="container Level{levels[2]}">
<div class="row">
{#each treeLevel2
.filter((x) => Object.values(x)[0].length > 2)
.map((x) => Object.keys(Object.values(x)[0][2])[0])
.filter((item, i, ar) => ar.indexOf(item) === i) as col, j}
<div class="col">
<div class="row justify-content-sm-center">
<div class="col">
<button class="btn btn-light btn-circle btn-xl">{col}</button>Einheitliche Formatierung:
Der Code sollte so formatiert sein, dass er leicht lesbar ist. Einheitliche Einrückungen, Leerzeichen und Zeilenumbrüche tragen dazu bei, den Code visuell ansprechend und leicht verständlich zu machen.
Kommentare sparsam und sinnvoll einsetzen:
Kommentare sollten nur dann eingesetzt werden, wenn es notwendig ist. Der Kommentar sollte das WARUM einer bestimmten Vorgehensweise erklären und nicht das WAS. Der Code sollte in sich selbsterklärend sein.
Hier ein Beispiel für Kommentare aus der Svelte Komponente:
// treeLevel represents the part of the complete tree that is selected by the user. It is base for the HTML rendering.
// Based on allLabels the Sankey UI is rendered with a button group
// Based on the uniqueLabels the decision arrows are shown and made interactivelyTestbarer Code:
Code sollte so geschrieben sein, dass er einfach getestet werden kann. Testen ist ein integraler Bestandteil des Clean-Code-Ansatzes. Der Code sollte so gestaltet sein, dass Tests leicht erstellt und gewartet werden können. Das Schreiben von Tests hilft nicht nur, Fehler frühzeitig zu erkennen, sondern dient auch als Dokumentation für die beabsichtigte Verwendung des Codes.
Durch die beliebige Veränderung des beispielhaften Testobjekts „Entscheidung für ein geeignetes Schwimmbad“ kann die Funktionalität der Svelte Komponente geprüft und beliebig angewendet werden.
const tree = {
Swimming: {
name: "DecisionforSwimmingPool",
type: "default",
complete: [
{
Eschersheim: [
{ Crowded: "Yes" },
{ Distance: "<10min" },
{ FreeParking: "Yes" },
{ Price: "3,30€" },
],
},
{
Brentanobad: [
{ Crowded: "Yes" },
{ Distance: "<10min" },
{ FreeParking: "No" },
{ Price: "3,30€" },
],
},
{
Taunabad: [
{ Crowded: "No" },
{ Distance: ">10min<20min" },
{ FreeParking: "Yes" },
{ Price: "4€" },
],
},
{
Kronberg: [
{ Crowded: "No" },
{ Distance: ">10min<20min" },
{ FreeParking: "Yes" },
{ Price: "3€" },
],
},Und jetzt automatisiert…
So viel zu den Grundlagen und der Theorie der Clean-Code-Prinzipien, demonstriert anhand eines Anwendungsbeispiels. Um nun die beschriebenen Prinzipien für größere Softwareprodukte standardisiert und teamübergreifend anwenden zu können, eignet sich die Integration von Static Code Analyzer Tools, wie beispielsweise SonarQube, in die Code Auslieferungs-Pipeline. Dieser automatisierte Auslieferungsprozess inkludiert Überprüfungen nach definierten Clean-Code-Heuristiken wie Code Smells oder Vulnerabilities bereits während der Entstehungsphase vor jedem Commit bis zu den Review-Prozessen und Quality Gates.
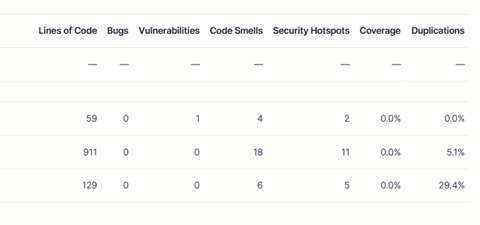
SonarQube ist ein automatisiertes Clean-Code- und Code-Review-Tool, welches sich in DevOps-Produktionszyklen nahtlos integrieren lässt, um qualitativ hochwertigeren Code ausliefern zu können. Hierbei werden Clean-Code-Paradigmen für über 30 verschiedene Programmiersprachen angewendet. Diese beinhalten programmiersprachenbezogene Formatierungs- oder Benennungsrichtlinien, Prüfungen auf atomare Zweckmäßigkeit der abgebildeten Funktion sowie unnötig eingebaute Komplexität. Darüber hinaus evaluiert SonarQube die Testabdeckung, beispielsweise durch Unittests oder die Anzahl von Code-Wiederholungen in Code-Blöcken oder -Zeilen (Quelle: https://www.sonarsource.com/products/sonarqube/).
Folgendes Bild zeigt die Übersicht der erkannten Clean-Code-Auffälligkeiten des neu bereitgestellten Codes.
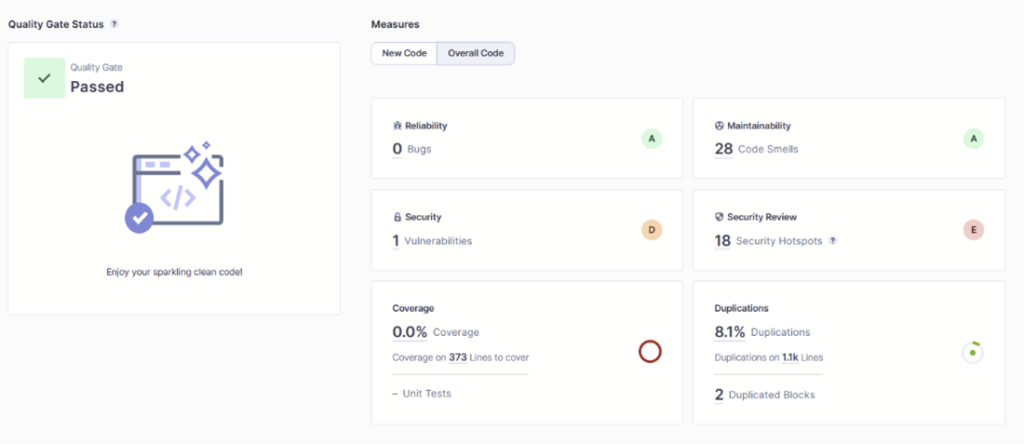
Fazit
C. Martin erklärt in seinem Buch, dass es durchaus legitim ist, zuerst die volle Funktionsweise des Codes sicherzustellen. Trotzdem ist aus seiner Sicht das Erzeugnis nicht abgeschlossen, solange die Clean-Code-Prinzipien nicht angewendet werden.
Diese Perspektive kann aus meiner Sicht nicht nur ausschließlich für die Softwareentwicklung, sondern für die gesamte DevOps-Welt angewendet werden, da überall wo Code produziert wird, die Wartbarkeit zwingend erforderlich ist.
Es ist völlig in Ordnung, sich den weniger sauberen Code-Snippets anzunehmen und schrittweise den Code wartbarer zu gestalten. Dieser Artikel soll als Motivation dienen, auch solche, system-nahen Codeabschnitte sorgfältig zu überarbeiten.