
In der Welt der vollautomatisierten und unveränderbaren Infrastruktur (Immutable Infrastructure), geht man davon aus, dass die Infrastruktur durch Skripte (Infrastruktur als Code) konfiguriert ist und keine manuellen Eingriffe stattgefunden haben. Container sind im Einsatz und diese brauchen ja bekannterweise kein Backup. Backup und Disaster Recovery sind also Themen von gestern und haben im Rechenzentrum der Zukunft keinen Platz mehr… oder?
Naja. Vielleicht nicht ganz.
Dass Container kein Backup benötigen, ist mittlerweile ein gut etabliertes Missverständnis. Den unveränderbaren Status muss man festhalten und wiederherstellen können. So ganz unveränderbar scheint die Infrastruktur wohl auch eher nicht.
Ransomware existiert nach wie vor und Human Errors können auch im Code etabliert werden. Was tun? Falsche Zugriffsrechte im Kubernetes Cluster und alle Konfigurationsfiles löschen? Wichtige Zertifikate verlieren? Gerade in der Welt der dynamischen Infrastruktur passieren Änderungen sehr schnell, ob beabsichtigt oder nicht. Umso wichtiger ist Versionssicherheit und Backups von relevanten Files und Zuständen.
Allerdings haben sich die Anforderungen Richtung Backup und Recovery verändert. Daher sollte man in der Welt von CICD-Pipelines, Infrastrucure as Code und Containern etwas umdenken.
Ein weiterer Punkt, der zu beachten ist, ist die Autorisierung und Authentifizierung im Bereich der Automatisierung und der automatischen Anbindung von Backup Systemen. Hierfür werden zentrale Key-Value Store (Vault Systeme) verwendet.
Konsistente Applikationen
Wie immer sollte der erste Blickwinkel, der aus der Applikationsschicht heraus sein. Die Anwendungen sind der Service, welcher nach außen bereitgestellt wird. Dieser muss konsistent gebackuped werden. Laufen diese Applikationen nun in Containern, sind die Informationen in diesen erstmal stateless, d.h. der Code ist so geschrieben, dass die Container „weggeschmissen und neugestartet“ werden können. Doch woher kommt der Inhalt der Container? Die Images und Konfigurationsfiles, die herangezogen werden, müssen sicher abgelegt werden. Zusätzlich gibt es Anbindungen von persistenten Daten, die der Applikation zur Verfügung steht. Das heißt Volumes, Datenbanken und Objekte werden angebunden. Dazu später mehr. Ein weiterer Aspekt ist die Kommunikation zwischen den Containern. Diese ist jedoch enorm anwendungsspezifisch und wird hier erstmal nicht weiter beleuchtet.
Immutable Infrastructure
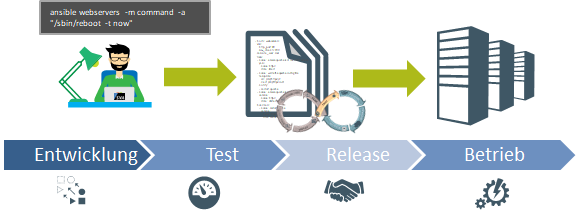
Abbildung1: Ablauf der Pipeline: von Entwicklung zum Betrieb
In der Welt der vollautomatisierten Infrastruktur wird die Infrastruktur in Codefiles beschrieben und per CICD Pipeline ausgerollt. Alle Textfiles werden in einem oder mehreren Source-Code-Management-Tools (meistens Git) abgelegt. Binary Files sind in einer Registry/Artifactory gesichert. Hierzu gehören Infrastruktur Files (z.B. Terraform), Konfigurationsfiles (z.B. Ansible, Puppet) und Docker Images. Beide Instanzen müssen gebackuped werden.
Dabei ist zusätzlich zu beachten, dass die Konfiguration der Pipeline selbst (Source Code Management, Workflow Engine, Artefakt Storage, Test Frameworks, Full-Stack Monitoring), sowie der Ablauf der Pipeline in einem Konfigurationsfile abgelegt ist und in einem Recovery-Fall als erstes wiederhergestellt werden muss, um die restliche Infrastruktur aufbauen zu können. Die Umgebungen Develop, Test, Stage und Production können separat betrachtet und gesichert werden. Testverfahren und deren Ergebnisse sind oft besonders zu beachten, um Compliance-Richtlinien und Revisionssicherheit zu gewährleisten.
Es sollte an dieser Stelle auch nicht unkommentiert bleiben, dass der Bezug der Infrastruktur im Public Cloud Bereich oft als Managed Service verstanden wird, bei dem man sich nicht um Backups kümmern muss. Dies ist nicht der Fall und sollte in jedem Fall beleuchtet werden.
Also insgesamt ist bei unveränderbarer Infrastruktur insbesondere darauf zu achten Konfigurationsfiles (nach ITIL: CI – Configuration Items) zu sichern. In der Regel liegen diese in einen Repository in Git. Diese Sicherung ist nur dann ausreichend, wenn es keinerlei manuelle Konfiguration gab.
Container
Abbildung 2: Container
In der Welt der Container müssen weiterhin alle Datenstores gesichert werden. Das bedeutet, ein Backup der angebundenen Datenbanken und Datenvolumes ist nach wie vor unabdingbar.
Volume (NAS, Block, Object/S3) werden in der Container Welt mit Hilfe des CSI (Container Storage Interface) angebunden, einem generischen Treiber. Dieser wird ebenfalls genutzt um konsistente Backups zu gewährleisten. Hier muss Herstellerspezifisch evaluiert werden welche Produkte diese Funktionalität unterstützen bzw. gewährleisten. Für eine konsistente Sicherung muss die Ansteuerung dessen von der Applikation bis zum Storage berücksichtigt und umgesetzt werden.
![]()
Abb. 3: Container Storage Interface (CSI) for Kubernetes GA (Quelle: hier )
Die Blueprints der Container selbst, d.h. Images in der Registry und Applikationsfiles im Artifactory Storage, müssen gesichert und der Restore-Weg getestet werden.
Als letzter Aspekt sollte noch beachtet werden, dass zur Wiederherstellung die Information wo und wann welche Anwendung läuft relevant ist. Hierfür ist die Information welcher Microservice in welchem Container und auf welchem Node läuft zu beachten. Snapshots und Backups des Service Manifests (YAML-File im Git), ETCD (Key-Value Datenbank von K8s, Container und Volume Informationen) muss beachtet werden. Bei verschiedenen Kubernetes Anbietern ist dieser Aspekt bereits beachtet und Werkzeuge stehen zur Verfügung.
Interesse am Thema DevOps, kurz und knapp in 5 Minuten? Hier geht es zum Artikel: DevOps ist nicht mehr wegzudenken!