Christian Stankowic
Christian Stankowic Schon lange leben wir in einer kurzlebigen IT-Welt, in welcher in immer kürzerer Zeit immer mehr Infrastruktur bereitzustellen und regelkonform zu konfigurieren ist. Während früher ein System-Administrator durchschnittlich vielleicht 20 Server zu verwalten hatte, sind es heute eher um die 200. Der Einsatz eines entsprechenden Tools ist also schlichtweg notwendig, um dem Zoo an Systemen Herr zu werden – ohne Automatisierung kommt man hier nicht weit.
Configuration Management ist hier ein wichtiges Schlagwort. Der dazugehörige Markt ist groß; so tummeln sich hier viele verschiedene Vertreter, wobei Ansible, Puppet, Salt und Chef zu den derzeit prominentesten Produkten zählen. Mit SUSE Manager gibt es ein Werkzeug zur Systemverwaltung, welches schon seit Version 3 aus 2016 einen vollintegrierten Salt-Master mitbringt. Dieser Master fungiert als Kernkomponente des Configuration Management und ermöglicht eine Konfiguration der verwalteten Systeme in Echtzeit – doch dazu später mehr.
Abbildung 1: SUSE Manager 4-Hauptmenü
Viele Configuration Management-Produkte basieren auf einem reaktiven Handlungsprinzip: ein Administrator nimmt eine Änderung vor und diese wird – sofern notwendig – auf den betroffenen Systemen entsprechend umgesetzt. Allerdings ist reaktives Handeln manchmal zu wenig. Vor allem komplexe IT-Applikationen haben besonders kritische Komponenten, die im Fehlerfall schnelles Handeln erfordern.
Zur Vermeidung von Ausfällen gibt es mehrere Ansätze – ein häufig gewählter ist das redundante Auslegen von Komponenten. So könnte man beispielsweise statt eines Backend-Webservers einfach mehrere aufsetzen und hinter einem Load-Balancer betreiben, um einen automatischen Lastenausgleich vorzunehmen. Je nach Applikation lassen sich manche Komponenten jedoch nicht ohne Weiteres redundant auslegen oder der damit verbundene zusätzliche Verwaltungsaufwand ist zu hoch.
Ein weiterer Ansatz ist die automatische Reaktion auf bekannte Status-Veränderungen und Fehler – gerne auch als Event-driven Infrastructure bezeichnet. Hier ist der Ansatz ein komplett anderer – anstelle manuell ausgelöster Änderungen, um das Problem zu beheben (beispielsweise Neustarten einer abgestürzten Software-Komponente, Bereinigen einer vollgelaufenen Festplatte, …) reagiert das Configuration Management automatisch. Es erkennt, welche Systemparameter sich geändert haben (z.B. Dienst gestoppt, Festplatte voll, …) und kann vorkonfigurierte Gegenmaßnahmen einleiten (z.B. Dienst starten, Festplatte bereinigen). Wenn sich ein solcher Ausfall nachts ereignet muss kein Bereitschaftsmitarbeiter mehr wachgeklingelt werden. Durch definierbare Schwellwerte kann eine Gegenmaßnahme bereits vor einem Ausfall des betroffenen Dienstes eingeleitet werden – Endanwender können dann den Dienst ohne Beeinträchtigung weiter nutzen.
Natürlich sei an dieser Stelle darauf hingewiesen, dass nicht jede Applikation und jeder Fehlertyp zwangsläufig für diesen Ansatz geeignet ist. Einige kritische Applikationen erfordern im Fehlerfall immer ein manuelles Zutun, um noch größeren Schaden zu verhindern (beispielsweise Datenbankfehler in verteilten ERP-Systemen) – hier könnte eine automatische Fehlerbehebung durchaus großen Schaden anrichten. Für zahlreiche Anwendungen und typische „Standardfehler“ – also wohl bekannte und dokumentierte Szenarien – bietet sich der Reparatur-Automatismus allerdings durchaus an.
SUSE Manager 101
SUSE Manager ist das zentrale Systemverwaltungstool rund um SUSE Linux-Infrastruktur. So können neue SUSE Linux-Systeme aufgesetzt (physisch, virtuell oder auch als Container), konfiguriert und verwaltet werden. Registrierte Systeme beziehen Software-Pakete und –Patches fortan vom zentralen SUSE Manager und nicht aus externen Quellen. Um sicherzustellen, dass artverwandte Systeme (z.B. alle Entwicklungssysteme einer spezifischen Applikation) lediglich getestete Patches erhalten, kann der Administrator mithilfe des Content Lifecycle Managements Systemlandschaften und Reihenfolgen vorgeben und Patch-Stände einfrieren, ein Beispiel:
Entwicklung → Test → Produktion
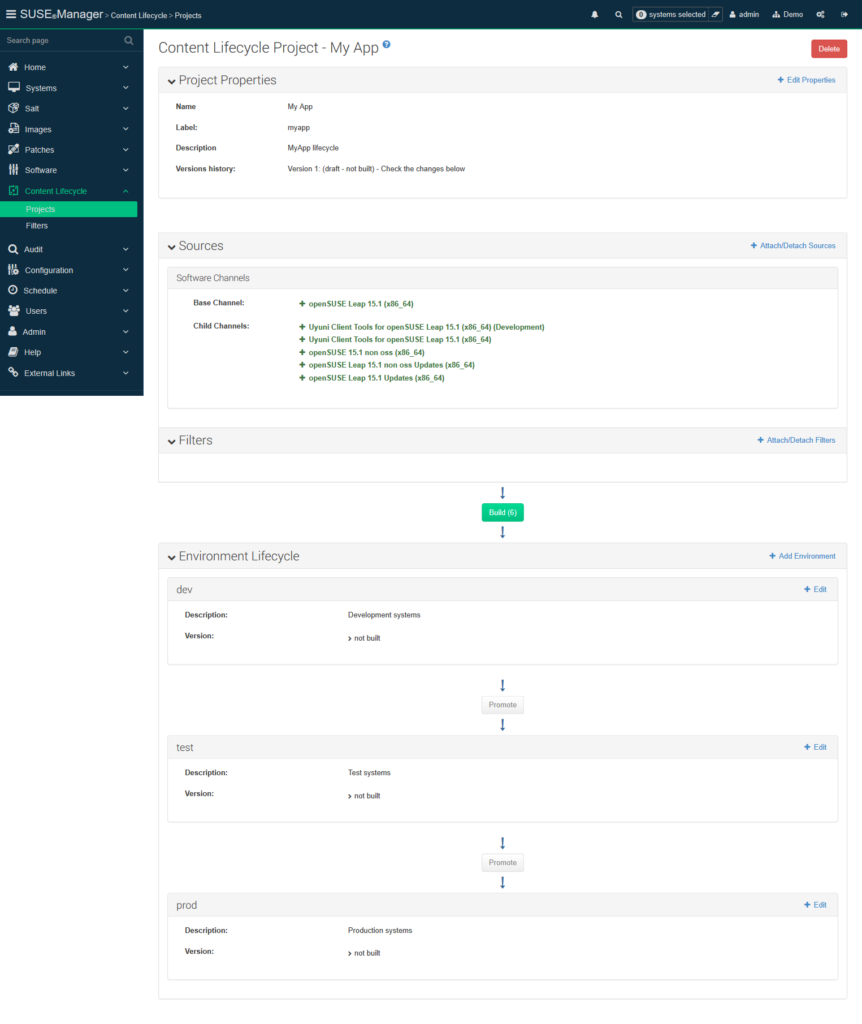
Abbildung 2: Ein Content Lifecycle Project definiert Systemumgebungen und Patchstände
Hier wurden Inhalte aus mehreren openSUSE 15.1-Kanälen an einem spezifischen Tag eingefroren und einem Content Lifecycle Project zugewiesen. Diesem Projekt wurden die Umgebungen „Test“, „Entwicklung“ und „Produktion“ zugewiesen. Patches werden fortan der Testumgebung zugeordnet, bevor diese nach erfolgten Tests den Entwicklungs- und Produktionssystemen zugänglich gemacht werden.
Patches können komfortabel einem oder mehreren Systemen zugewiesen werden – entweder per Web-Oberfläche oder per API, die fast alle Funktionen des Produkts ansteuern kann. Bestehende Systeme können mittels OpenSCAP auf Einhaltung etwaiger Sicherheitsrichtlinien überprüft werden.
Die Konfiguration der registrierten Systeme kann mittels Salt erfolgen, da SUSE Manager ein vollständiger Salt-Master ist.
Salt in a nutshell
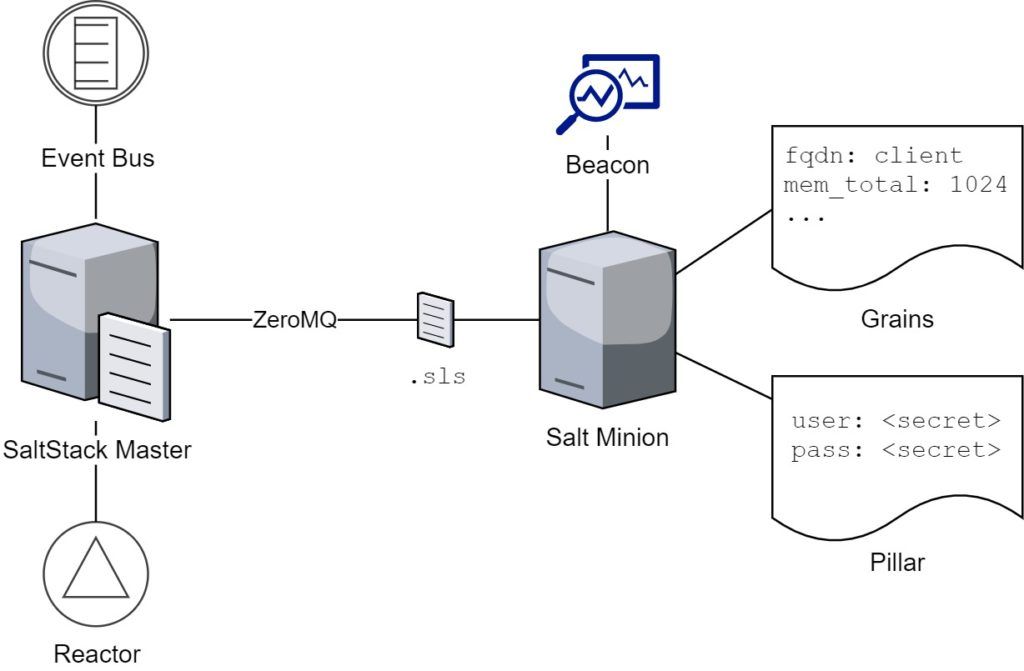
Abbildung 3: Aufbau und Komponenten eines Salt Master-/Minion-Setups
Salt (oder auch SaltStack) ist ein in Python geschriebenes Configuration Mangement-Tool, es erschien zuerst 2011 und basiert prinzipiell auf dem Server-/Client-Prinzip, kann jedoch auch ohne Server benutzt werden. Während der Server Salt-Master genannt wird, werden die zu verwaltenden Systeme als Minions bezeichnet. Die Kommunikation zwischen Master und Minions erfolgt über eine AES-Verschlüsselung, als Protokoll dient ZeroMQ, welches eine sehr hohe Geschwindigkeit bietet. Als Clients werden unter anderem folgende Betriebssysteme unterstützt:
- IBM AIX
- Debian / Ubuntu
- RHEL / CentOS
- SLES / openSUSE
- Microsoft Windows
- Oracle Solaris
Clients können entweder über die Minion-Software oder alternativ nur via SSH konfiguriert werden. Hierbei sinkt jedoch die Kommunikationsgeschwindigkeit durch den Protokoll-Overhead.
Wie andere Infrastructure as Code-Lösungen definiert auch Salt Soll-Zustände, die dann während der Ausführung umgesetzt werden. Salt nennt diese Zustände States, erfasst diese im YAML-Format und verpasst diesen die Datei-Endung .sls (Salt States). Diese States beinhalten zu konfigurierende Ressourcen und deren Spezifika – beispielsweise Benutzerkonten mit vordefinierten Gruppen. Mehrere solcher States können zu einem übergreifenden High State zusammengefasst werden. Im Zusammenspiel mit SUSE Manager umfasst der High State noch mehrere interne Gegebenheiten – beispielsweise das Entfernen von fremden, externen Software-Repositories und das Installieren von benötigten Paketen zur Systemverwaltung.
States können modular geschrieben werden, indem sie system-relevante Informationen referenzieren – so kann man beispielsweise die Heap-Konfiguration einer Java-Anwendung abhängig vom System-Arbeitsspeicher gestalten, ohne den konkreten Wert kennen zu müssen. Salt inventarisiert bestehende Systeme und stellt zahlreiche Meta-Informationen, wie beispielsweise CPU-, Betriebssystem- und Netzwerk-Spezifika zusammen und nennt diese Grains; Anwender von Puppet und Ansible kennen diese Funktion bereits als Facts. Sowohl States als auch verteilte Dateien können mithilfe des Jinja-Frameworks mit Grains und anderen Inhalten befüllt werden.
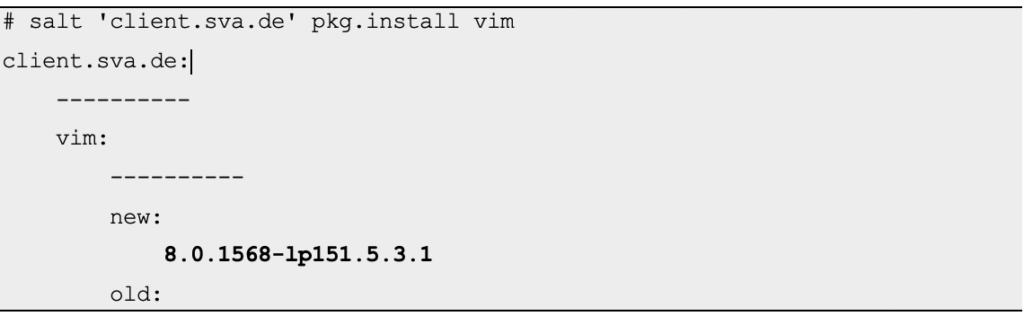
Salt bietet verschiedene Arten von Modulen, von welchen zwei für dieses Beispiel besonders relevant sind. Während State Module Soll-Zustände über .sls-Dateien definieren, dienen Execution Module zur Einsicht und Konfiguration in Echtzeit. Diese werden in der Regel über die Kommandozeile auf einem oder mehreren Systemen parallel ausgeführt – ideal für ad-hoc Administration.
Ein Beispiel:
# salt 'client.sva.de' pkg.install vim
client.sva.de:
----------
vim:
----------
new:
8.0.1568-lp151.5.3.1
old:
Hier wird auf dem registrierten Client mittels State Module pkg.install das Paket vim installiert. Statt eines konkreten Hostnames könnten auch Netzadressen, Wildcards oder reguläre Ausdrücke verwendet werden – beispielsweise um die Aktion auf mehreren Systemen auszuführen.
Das State Module-Pendant hierzu sieht wie folgt aus:
vim: pkg.installed
Weitere Execution Module und deren Parameter finden sich in der offiziellen Dokumentation, die natürlich auch State Module beinhaltet.
Pro Minion wird ein verschlüsselter Key-Value-Store gepflegt: Pillars. Dieser empfiehlt sich für die sichere Ablage von Passwörtern und anderen sensiblen Informationen.
In der Salt-Community gibt es vordefinierten Code, der für eigene Systeme übernommen werden kann. Dieser Code wird Formulas genannt und kann komfortabel über die SUSE Manager Web-Oberfläche parametrisiert werden. Neben den Community-Inhalten liefert auch SUSE einige Formulas aus, beispielsweise zur Konfiguration der Lokalisierung.
Event-driven Infrastructure
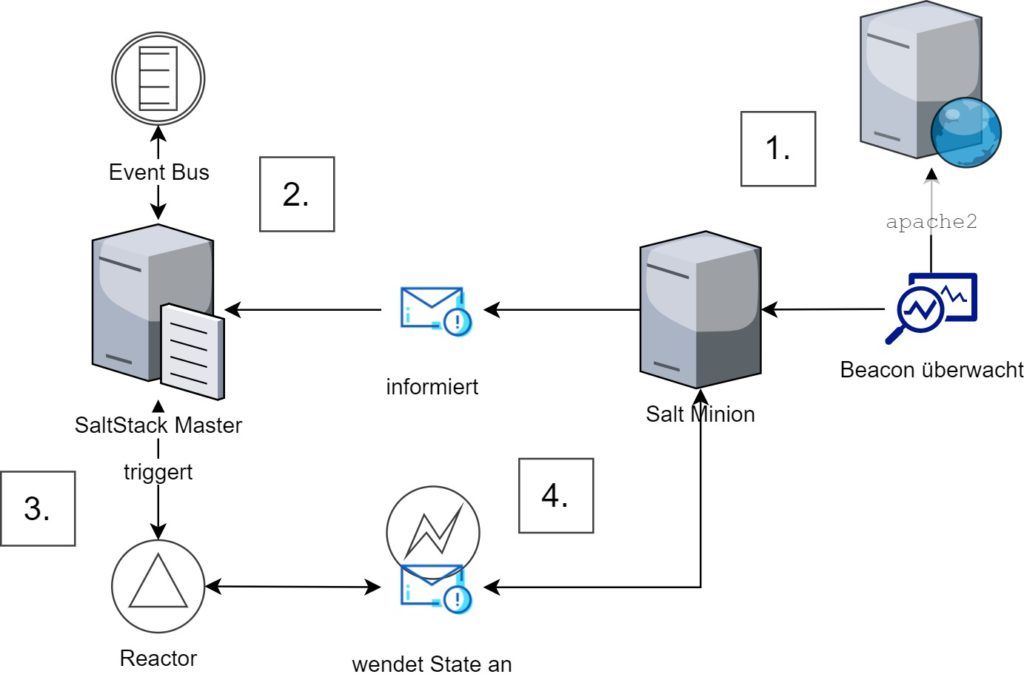
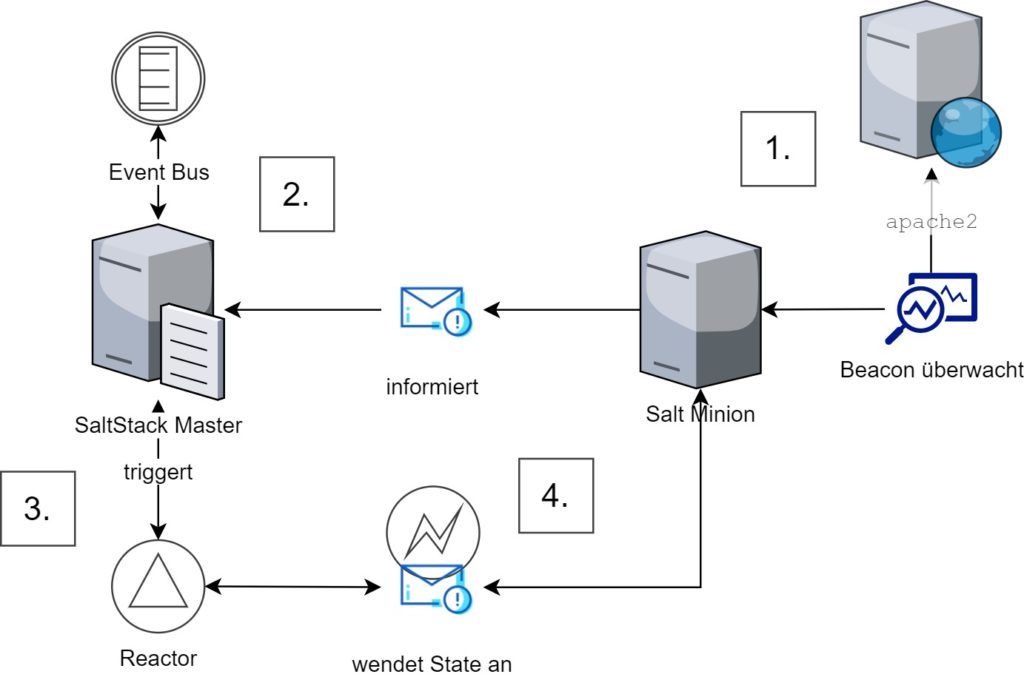
Abbildung 4: Das Zusammenspiel zwischen Salt Minion, Beacons, Salt Master, Event-Bus, Reactor und State
Salt verfügt über ein bidirektionales Event-Bus-System. Dieses dient nicht nur zur internen Kommunikation, sondern kann auch von Ereignissen auf Client-Systemen angesteuert werden und sich in Drittanbieter-Software integrieren. So könnte man beispielsweise eine automatische Chat-Benachrichtigung im Falle eines abstürzenden Dienstes implementieren.
Auf dem Salt-Master können Daten des Events-Busses wie folgt in Echtzeit angeschaut werden:
# salt-run state.event pretty=True
Jedes Event besteht aus einem eindeutigen Tag (beginnend mit salt/) und dazugehörigen Daten, die das Event beschreiben. Ein Beispiel:
salt/minion/client.sva.de/start {
"_stamp": "2020-03-26T15:57:25.896755",
"cmd": "_minion_event",
"data": "Minion client.sva.de started at Thu Mar 26 16:57:25 2020",
"id": "client.sva.de",
"pretag": null,
"tag": "salt/minion/client.sva.de/start"
}
Hier wurde der Salt-Minion eines Client-Systems gestartet – eine Anmeldung am Salt-Master ist erfolgt.
Ein weiteres Beispiel – im folgenden Abschnitt wird das Execution Module test.ping ausgeführt, um die Erreichbarkeit des Clients zu überprüfen. Nachfolgend dann die daraus resultierenden Informationen im Event-Bus:
# salt 'client.sva.de' test.ping
client.sva.de:
True
…
salt/job/20200327095317115018/new {
"_stamp": "2020-03-27T08:53:17.120273",
"arg": [],
"fun": "test.ping",
"jid": "20200327095317115018",
"minions": [
"client.sva.de"
],
"missing": [],
"tgt": "client.sva.de",
"tgt_type": "glob",
"user": "sudo_vagrant"
}
salt/job/20200327095317115018/ret/client.sva.de {
"_stamp": "2020-03-27T08:53:17.256150",
"cmd": "_return",
"fun": "test.ping",
"fun_args": [],
"id": "client.sva.de",
"jid": "20200327095317115018",
"retcode": 0,
"return": true,
"success": true
}
Zuerst wird ein neuer Job (new) mit dem Kommando test.ping (fun) auf dem Zielsystem (tgt) registriert.
Die Antwort (ret) enthält neben dem Kommando auch den Return-Code (retcode) sowie eine Aussage darüber, ob der Job erfolgreich ausgeführt wurde (success).
Interessant sind auch die Zeitstempel (_stamp). Hier zeichnet sich die hohe Geschwindigkeit des ZeroMQ-Protokolls ab – die Jobs haben nicht mal eine Sekunde angedauert.
Der Salt Minion ist in der Lage auf verschiedene System-Ereignisse (z.B. Dienst gestoppt, Datei überschrieben) zu reagieren und sogenannte Beacons an den Salt Master zu senden. Dieser empfängt die Nachricht über den Event-Bus und kann so auf das Ereignis in Echtzeit reagieren. In der Regel löst der Inhalt des Beacons einen Reactor aus; dieser kann dann auf eine Vielzahl von Aktionen zurückgreifen, wovon das Anwenden eines States die naheliegendste Lösung ist.
Möglichkeiten
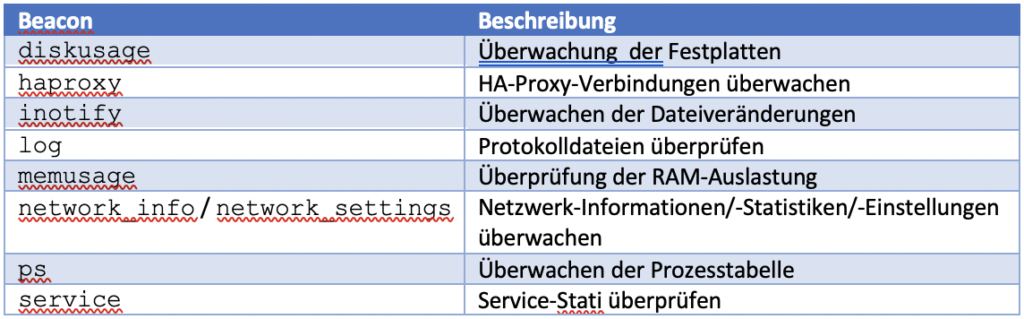
In der von SUSE Manager verwendeten Salt-Version 2019.02 gibt es unter anderem folgende Beacon-Typen:
| BEACON | BESCHREIBUNG |
|---|---|
| diskusage | Überwachung der Festplatten |
| haproxy | HA-Proxy-Verbindung überwachen |
| inotify | Überwachen der Dateiveränderung |
| log | Protokolldateien überprüfen |
| memusage | Überprüfung der RAM-Auslastung |
| network_info/ network settings | Netzwerk-Informationen /-Statistiken /-Einstellungen überwachen |
| ps | Überwachen der Prozesstabelle |
| service | Service-Stati überprüfen |
Eine vollständige Liste der unterstützten Beacon-Typen ist in der offiziellen Salt-Dokumentation zu finden.
Hieraus lassen sich einige Beispiele ableiten:
- Erweitern der Festplatte eines Datenbank-Servers, um ein Stoppen der Datenbank zu verhindern – ggf. als Zuarbeit, bis ein entsprechender Administrator den Ursprung des Problems behoben hat
- Hinzufügen eines weiteren HAProxy-Servers bei hoher Last
- Überprüfen der Applikationsintegrität und ggf. Zurückspielen von Inhalten bei geänderten Dateien
- Neustart eines Backend-Services bei Fehlern im Applikationsprotokoll
- Neustarten eines Dienstes im Fehlerfall
Beispiel-Szenario
Genug der Theorie – Zeit für einen Praxis-Test! Beispielhaft sollen hier folgende Komponenten aufgesetzt werden:
- Erstellen zweier VMs mit openSUSE Leap 15.1
- Hostnames: salt und client
- Erstellen eines Netzwerks zwischen beiden VMs
- Installation von Salt-Master in der salt VM
- Installation von Salt-Minion in der client VM
- Konfigurieren eines einfachen Apache-Webservers in der client VM
- Erstellen eines Beacons, der den Webserver und die angebotene Webseite beobachten und bei Ausfällen bzw. Überschreibungen den Salt-Master informiert
- Erstellen eines Reactors, der auf diese Beacons reagiert und Gegenmaßnahmen über States ansteuert
Um den Vorgang zu beschleunigen gibt es ein vorbereitetes Demo-Projekt auf GitHub. Mithilfe von Vagrant können die oben beschriebenen Aufgaben in knapp 20 Minuten automatisiert ausgeführt werden. Neben Vagrant werden noch Oracle VirtualBox und mindestens 4 GB Arbeitsspeicher benötigt.
Sobald die benötigte Software installiert wurde, genügt ein Klonen des Projekts via git bzw. Herunterladen und Entpacken des Repository-Archivs. Anschließend wird eine Kommandozeile geöffnet und in den soeben entstandenen Ordner gewechselt. Die Bereitstellung erfolgt mit dem Kommando:
$ vagrant up
Anschließend werden eine knapp 2 GB große openSUSE-Vorlage heruntergeladen und die oben erwähnten VMs erstellt und konfiguriert.
Nach Abschluss der Arbeiten können mithilfe des Kommandos vagrant ssh unter Angabe des Systemnamens (salt, client) Verbindungen zu den einzelnen Maschinen erfolgen:
PLAY RECAP ********************************************************************* client : ok=14 changed=10 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 $ vagrant ssh salt Last login: Fri Mar 27 10:29:06 2020 from 10.0.2.2 vagrant@salt:~> exit $ vagrant ssh client Last login: Fri Mar 27 10:29:10 2020 from 10.0.2.2 vagrant@client:~> exit
Der eingerichtete Webserver ist unter der Adresse http://localhost:8888 zu erreichen:
Abbildung 5: Startseite des Beispiel-Projekts
Zeit die automatische Reparatur im Fehlerfall auf Herz und Nieren zu überprüfen. Zuerst empfiehlt es sich ein zweites Terminal im Repository-Ordner zu öffnen, eine SSH-Verbindung zum Salt-Master herzustellen und den Event-Bus zu öffnen:
$ vagrant ssh salt $ sudo salt-run state.event pretty=True
Anschließend wird der Apache-Webserver im zweiten Terminal nach erfolgtem Login auf client gestoppt:
$ vagrant ssh salt $ sudo systemctl stop apache2 $ sudo systemctl status apache2 ● apache2.service - The Apache Webserver Loaded: loaded (/usr/lib/systemd/system/apache2.service; enabled; vendor preset: disabled) Active: inactive (dead) since Fri 2020-03-27 12:13:27 CET; 2min 7s ago …
Der Dienst ist definitiv gestoppt – nach einiger Zeit sind im Event-Bus folgende Informationen zu sehen:
salt/beacon/client.sva.de/service/apache2 {
"_stamp": "2020-03-27T11:18:51.362611",
"apache2": {
"running": false
},
"id": "client.sva.de",
"service_name": "apache2"
}
…
salt/job/20200327121916479907/new {
"_stamp": "2020-03-27T11:19:16.481179",
"arg": [
"restart_apache2"
],
"fun": "state.apply",
"jid": "20200327121916479907",
"minions": [
"client.sva.de"
],
"missing": [],
"tgt": "client.sva.de",
"tgt_type": "glob",
"user": "salt"
}
…
salt/job/20200327121916479907/ret/client.sva.de {
"_stamp": "2020-03-27T11:19:29.003396",
"cmd": "_return",
"fun": "state.apply",
"fun_args": [
"restart_apache2"
],
"id": "client.sva.de",
"jid": "20200327121916479907",
"out": "highstate",
"retcode": 0,
"return": {
"service_|-restart_apache2_|-apache2_|-running": {
"__id__": "restart_apache2",
"__run_num__": 0,
"__sls__": "restart_apache2",
"changes": {
"apache2": true
},
"comment": "Started Service apache2",
"duration": 29.102,
"name": "apache2",
"result": true,
"start_time": "12:19:31.798309"
}
},
"success": true
}
…
salt/beacon/client.sva.de/service/apache2 {
"_stamp": "2020-03-27T11:19:39.003396",
"apache2": {
"running": true
},
"id": "client.sva.de",
"service_name": "apache2"
}
Hier ist gerade folgendes passiert:
- Es wurde ein Beacon empfangen, welches besagt, dass der Dienst apache2 gestoppt wurde
- Es wurde ein neuer Job gestartet, welcher auf client den State restart_apache2 Dieser State sorgt dafür, dass Apache2 wieder gestartet wird
- Die Rückgabe des Jobs suggeriert, dass der Dienst erfolgreich wieder gestartet wurde
- Der Client sendet ein Beacon, welches über den gestarteten Dienst informiert
Doch ist dem wirklich so? Das Terminal des Clients gibt hierüber Aufschluss:
$ sudo systemctl status apache2 ● apache2.service - The Apache Webserver Loaded: loaded (/usr/lib/systemd/system/apache2.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2020-03-27 11:29:37 CET; 1min 16s ago …
Tatsächlich – der Dienst wurde neugestartet!
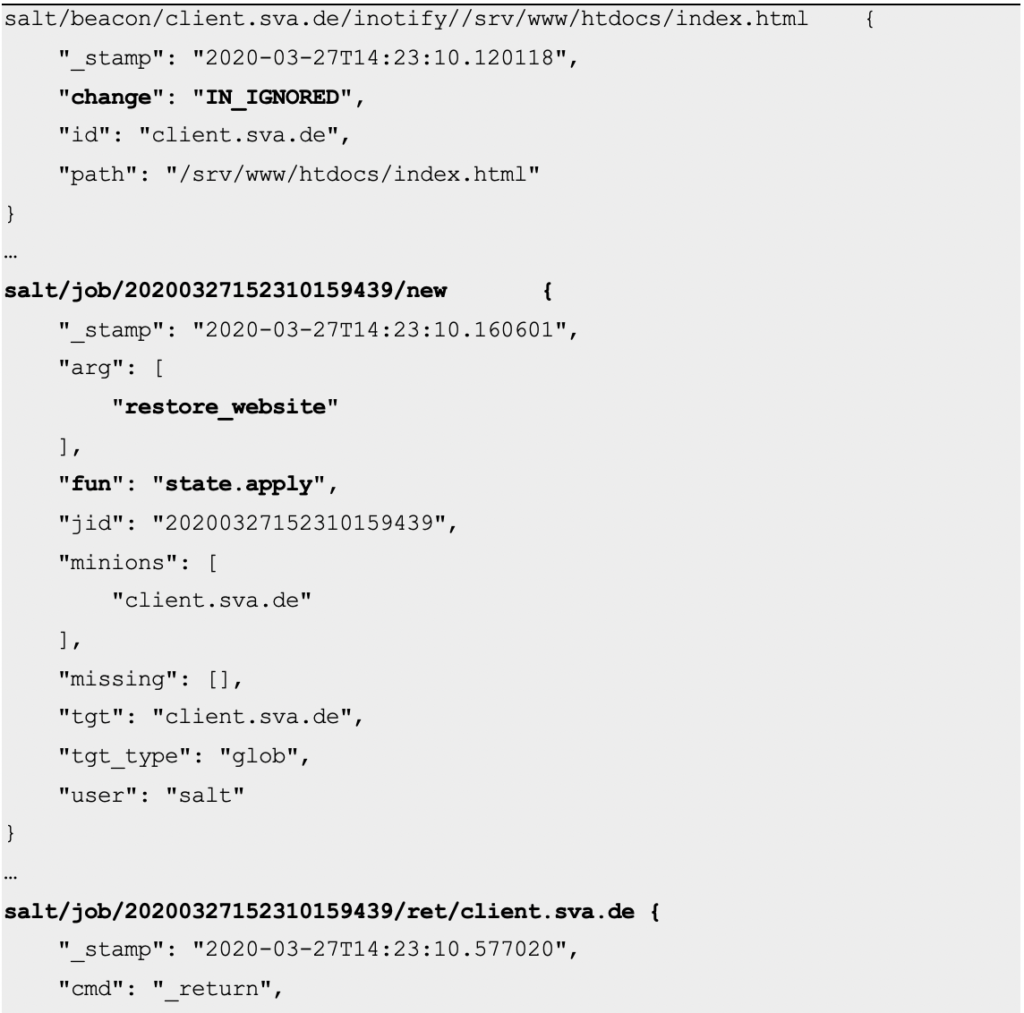
Doch wie verhält es sich nun mit überschriebenen Dateien? Was passiert, wenn die Startseite (/srv/www/htdocs/index.html) überschrieben wird?
$ sudo bash -c 'echo "Pinkepank" > /srv/www/htdocs/index.html'
Der Event-Bus zeigt sich hierüber gar nicht erfreut:
salt/beacon/client.sva.de/inotify//srv/www/htdocs/index.html {
"_stamp": "2020-03-27T14:23:10.120118",
"change": "IN_IGNORED",
"id": "client.sva.de",
"path": "/srv/www/htdocs/index.html"
}
…
salt/job/20200327152310159439/new {
"_stamp": "2020-03-27T14:23:10.160601",
"arg": [
"restore_website"
],
"fun": "state.apply",
"jid": "20200327152310159439",
"minions": [
"client.sva.de"
],
"missing": [],
"tgt": "client.sva.de",
"tgt_type": "glob",
"user": "salt"
}
…
salt/job/20200327152310159439/ret/client.sva.de {
"_stamp": "2020-03-27T14:23:10.577020",
"cmd": "_return",
"fun": "state.apply",
"fun_args": [
"restore_website"
],
"id": "client.sva.de",
"jid": "20200327152310159439",
"out": "highstate",
"retcode": 0,
"return": {
"file_|-restore_website_|-/srv/www/htdocs/index.html_|-managed": {
"__id__": "restore_website",
"__run_num__": 0,
"__sls__": "restore_website",
"changes": {
"diff": "…"
},
"comment": "File /srv/www/htdocs/index.html updated",
"duration": 73.971,
"name": "/srv/www/htdocs/index.html",
"pchanges": {},
"result": true,
"start_time": "15:23:10.505695"
}
},
"success": true
}
Hier wieder eine Zusammenfassung der einzelnen Schritte:
- Es wurde ein Beacon empfangen; es bestätigt eine Änderung an der Startseite
- Es wurde ein neuer Job gestartet, welcher auf client den State restore_website Dieser State sorgt dafür, dass die Startseite wiederhergestellt wird
- Die Rückgabe des Jobs bestätigt, dass die Datei aktualisiert wurde
Dabei ist Salt so schnell, dass man seine Mühe hat sicherzustellen, dass die Datei überhaupt überschrieben wurde. Noch während man den dafür nötigen Befehl (cat /srv/www/htdocs/index.html) eintippt wird die Datei im Hintergrund schon wieder überschrieben.
Fazit
Mithilfe von Salt lassen sich Systeme nicht nur reaktiv, sondern auch ereignisgesteuert verwalten – beispielsweise um fälschlicherweise überschriebene Dateien wiederherzustellen oder gestoppte Ressourcen wieder zu starten. Dies ist – vor allem – für bekannte wiederkehrende Fehler und Effekte ein geeignetes Werkzeug, um administrative Arbeiten zu automatisieren.
Weitere Links
Weitere Informationen finden sich hier:
- Salt-Tutorial über Event-driven infrastructure: https://docs.saltstack.com/en/getstarted/event/index.html
- Offizielle Salt-Dokumentation: https://docs.saltstack.com/en/2019.2/contents.html
- SUSE Manager-spezifische Salt-Dokumentation: https://documentation.suse.com/external-tree/en-us/suma/4.0/suse-manager/salt/salt-intro.html