
Der Bereich „Natural Language Processing“ (kurz NLP), ein Teilgebiet der künstlichen Intelligenz, beschäftigt sich mit der Verarbeitung natürlicher Sprache und hat sich seit der Einführung von Google’s BERT 2018 enorm verändert. Mit BERT hat sich eine neue Architektur für Neuronale Netze etabliert, die seitdem eine rapide Entwicklung mit der Veröffentlichung von immer mehr neuen Modellen mit sich gezogen hat. Diese gehören in die Kategorie der „Transformers“. Mit den Modellen wurden jegliche Benchmark-Rekorde, die zur Beurteilung der Qualität von Neuronalen Netze im Bereich des „Natural Language Processing“ existieren, gebrochen. Dazu gehören bspw. Aufgaben wie „Übersetzen“, „Fragen-Beantwortung“, „Zusammenfassen“ und „Klassifizieren“. Außerdem spielt die semantische Suche eine große Rolle und soll in diesem Artikel näher beschrieben werden.
Der Standard: Keyword-Suche
Die Art der Suche, die sich als Standard etabliert hat, ist die sogenannte Keyword-Suche. Dabei wird das Dokument nach den Worten in der Anfrage durchsucht. Sie bedient sich dabei zusätzlich dem TF-IDF Score, welcher die Reihenfolge der angezeigten Ergebnisse bestimmt. TF-IDF steht dabei für „Term-Frequency – Inverse Document Frequency“.
Die „Term-Frequency“ zählt die Frequenz der Worte. Dabei ist der „TF-IDF“-Score des Dokuments umso höher, je öfter die entsprechenden Worte der Suchanfrage im Dokument vorkommen.
Die „Inverse Document Frequency“ sorgt dafür, dass den Worten der Frage eine Art Relevanz gegeben wird. Kommt eines der Wörter nicht so oft in der Gesamtmenge der Dokumente vor, so gewichtet die „Inverse Document Frequency“ dieses höher. Somit bekommen Dokumente, die dieses „seltene“ Wort beinhalten, einen höheren Score. Worte wie zum Beispiel „und“, „der“, „will“ und „zwischen“ erhalten entsprechend einen niedrigen Score und damit eine geringere Relevanz.
Was semantische Suche besser macht
Wenn wir etwas suchen, wollen wir die entsprechenden Dokumente finden, unabhängig davon, wie wir die Wörter in der Suchanfrage schreiben oder kombinieren. Hier ist die semantische Suche mit BERT der richtige Ansatz. Sie kann im Idealfall den Kontext der Suchanfrage mit dem Kontext der vorliegenden Dokumente abgleichen, unabhängig davon ob in der Anfrage das entsprechende Keyword vorkommt.
Wir haben eine deutsche Variante von BERT entwickelt. Dabei wird das Kontextverständnis noch weiterentwickelt, indem BERT mit Daten trainiert wird, die ihm helfen semantisch ähnliche Texte zu erkennen und zu bestimmen. Das grundlegende Vorgehen basiert dabei auf dem Modell Sentence-BERT der TU-Darmstadt https://github.com/UKPLab/sentence-transformers.
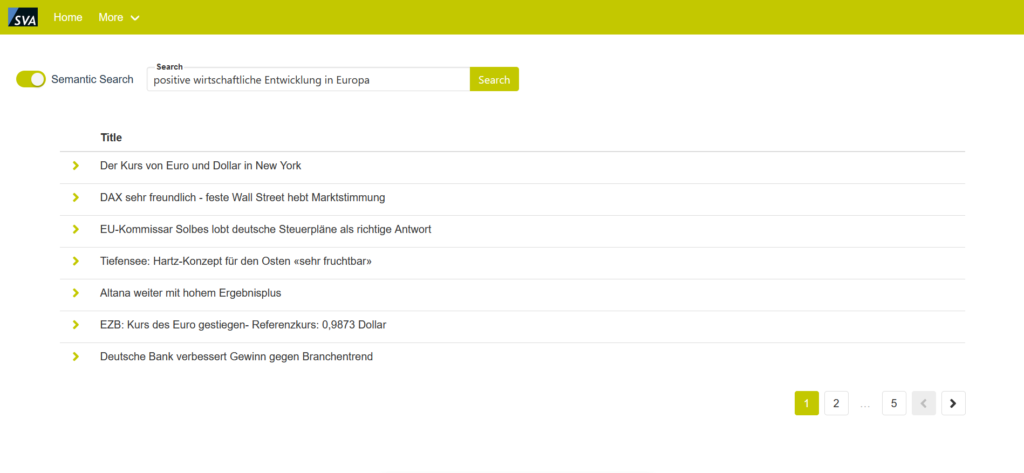
Abbildung 1: Beispiel für eine semantische Suchanfrage
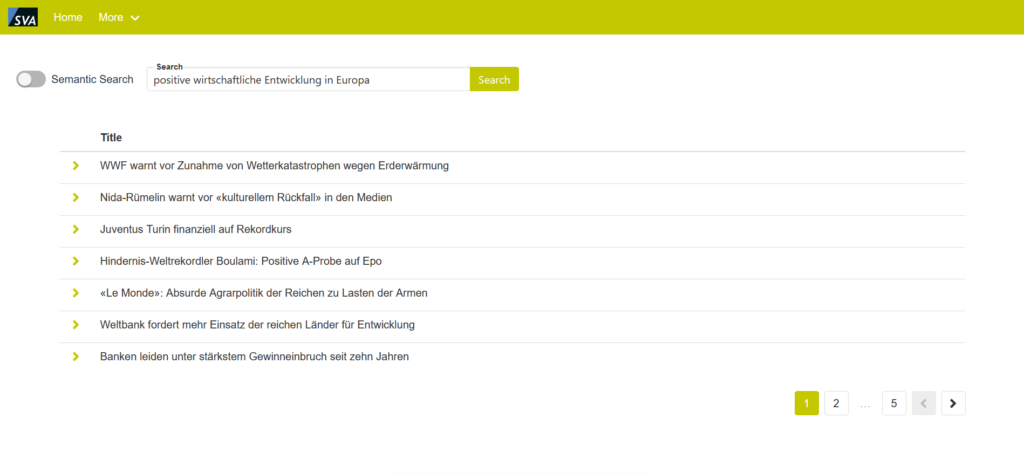
Abbildung 2: Beispiel bei einer klassischen Suchanfrage
Die Demo
Um die Unterschiede anhand eines Realbeispiels zu zeigen, haben wir eine Demo-Applikation entwickelt. Es handelt sich dabei um eine Microservice Architektur bestehend aus mehreren Containern. Das Frontend wurde mit Vue.js und dem Framework Buefy entwickelt. Als Suchmaschine dient dabei Elasticsearch, das seit Version 7.3 die Möglichkeit bietet, neben Dokumenten auch Dokumentvektoren zu speichern. Diese können mit Hilfe eines Ähnlichkeitsmaß der Suchanfrage zugeordnet werden.
Als grundlegendes Modell nutzen wir dabei eine von uns auf deutschem Text trainierte „RoBERTa“ („Robustly Optimized BERT Pretraining Approach“) Variante, die von uns mit maschinell übersetzten NLI und STS-B Daten weiter verfeinert wurde. Momentan arbeiten wir an einer Version, die auf kleingeschriebenem Text trainiert ist. So wird eine semantische Suche ermöglicht, bei der nicht auf Groß- und Kleinschreibung geachtet werden muss, und trotzdem sehr gute Ergebnisse erzielt werden.
Wie die Bilder zeigen, schafft es die Semantische Suche beeindruckende Ergebnisse zu erzielen. Mit der Eingabe von wenigen Worten können Dokumente gefunden werden. Wir müssen nur mit unserer Suchanfrage den Kontext treffend beschreiben. Entsprechend können wir, je genauer wir den spezifischen Kontext beschreiben, die entsprechenden Dokumente noch besser herausfiltern.
Das soll nicht heißen, dass die Keyword-Suche prinzipiell versagt. Sie kann der semantischen Suche in den Fällen überlegen sein, in denen wir genau wissen, welche Worte in den Dokumenten vorkommen. Also bei kleineren, eher homogenen Text-Datensätzen. Bei einer größeren Anzahl von heterogenen Text-Datensätzen, wie bei News-Artikeln, kann die semantische Suche uns entsprechend unterstützen Dokumente zu finden, die wir mit der Keyword-Suche im schlimmsten Fall sogar gar nicht gefunden hätten.
Wir bieten
SVA bietet neben der semantischen Suche noch weitere Services, die sich mit der Verarbeitung natürlicher Sprache befassen. Dazu gehören bspw. das Klassifizieren von Texten (bspw. für Fake News Erkennung, Hate-Speech), Named-entity recognition (NER), Stimmungslagen-Analyse und Fragen-Beantwortung. Letzteres Feature ist ebenfalls in der Demo eingebaut (Siehe Bilder unten). In der Suchmaske wird die Frage eingegeben und die semantische Suche findet das zur Frage passende Dokument. Mit einem Klick auf „Give Answer“ wird aus dem Text mit einem RoBERTa Modell, das für diesen speziellen Fall trainiert wurde, die Antwort auf die Frage rausgesucht. Man achte auf die Menge an Zahlen im Text, die das Modell gekonnt rausfiltern kann, um die richtige Antwort anzugeben.
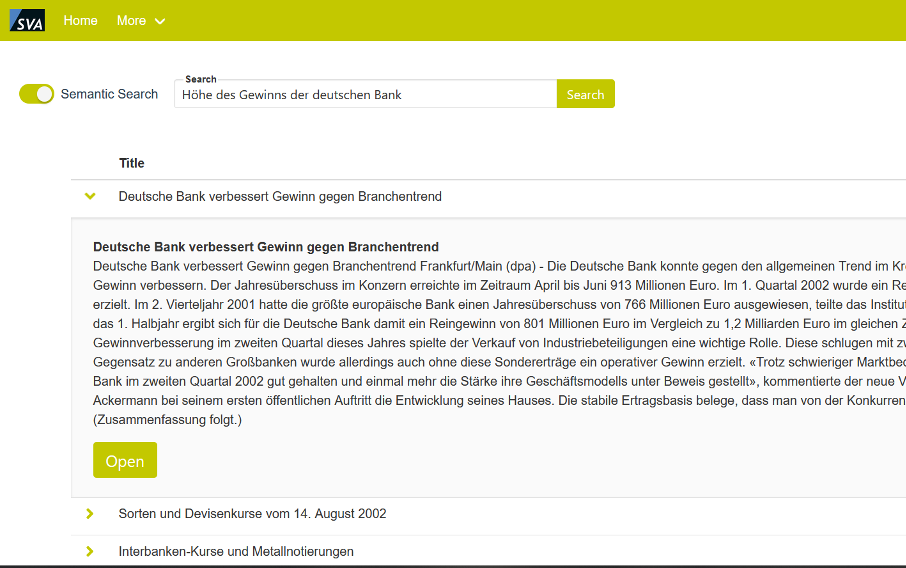
Abbildung 3: Darstellung des Suchergebnisses
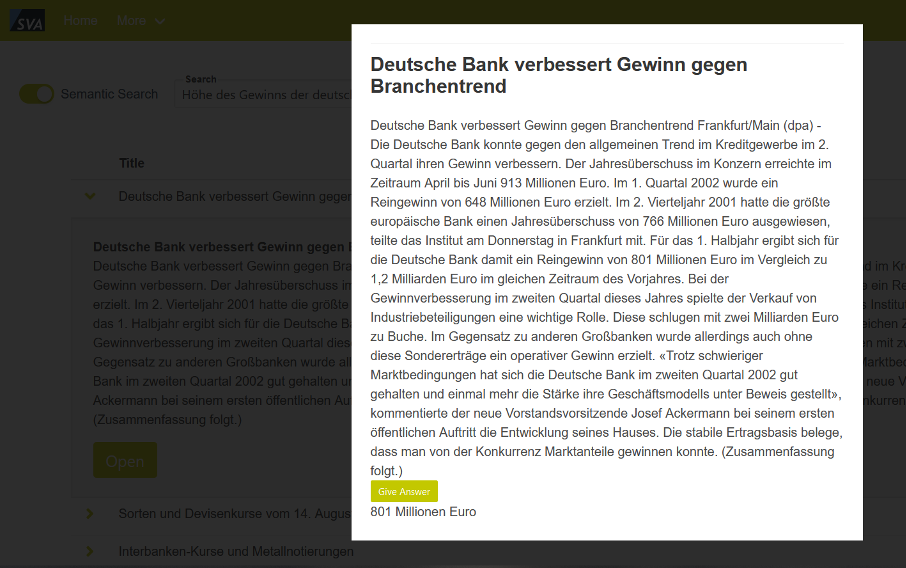
Abbildung 4: Darstellung nach der Fragestellung
Mit der Veröffentlichung dieses Blog Beitrages stellen wir auf huggingface.com, das von uns für mehrere Tage auf 24 Gb deutschen Textdaten trainierte deutschsprachige RoBERTa Modell öffentlich zur Verfügung, um einen Beitrag für die Open Source Community zu leisten.