

Durch die Vorarbeit der Kolleg:innen hinsichtlich einer automatisierten Installation von OpenShift auf Basis von Nutanix, wurde die NVIDIA-Fachabteilung von SVA hellhörig. „Probleme sind Chancen und in jeder Chance verbergen sich Probleme.“ lautet ein schönes Zitat. Chancen wie diese können genutzt werden, um sich mit Kolleg:innen zusammen den Problemen zu stellen und gemeinsam Lösungen zu finden und diese weiterzuentwickeln. Durch das Fundament der Partnerschaft mit NVIDIA sowie einer fertig installierten OpenShift Umgebung basierend auf Nutanix AHV, zeichnete sich eine Idee ab: die Arbeiten im SVA Lab starteten mit einem internen Hackathon.
Idee
Die Basiseigenschaften des angestrebten Ziels lassen sich wie folgt beschreiben:
Zur Reduzierung der Komplexität und, um die Lösung einfacher managen zu können, beschreibt die idealisierte Zielumgebung eine supportete All-In-One Enterprise-Lösung basierend auf Nutanix AHV, OpenShift und NVIDIA Grid GPUs. Um die Produkte optimal miteinander zu kombinieren, soll der Installationsprozess aller Komponenten reproduzierbar und automatisiert erfolgen. Als Basis fungiert dabei die Nutanix HCI-Plattform, um später auf Infrastruktur-Ebene möglichst einfach weiterskalieren zu können. Damit Microservice-Anwendungen möglichst ohne Einschränkungen bereitgestellt werden können, wird OpenShift als Containerplattform eingesetzt, welche sich ebenfalls einfach skalieren lässt. Ist die Automation des Stacks abgeschlossen, befähigt die entstandene Infrastruktur die Hardware und die durch OpenShift orchestrierten Microservices mit den einfachsten Mitteln kosteneffizient zu skalieren.
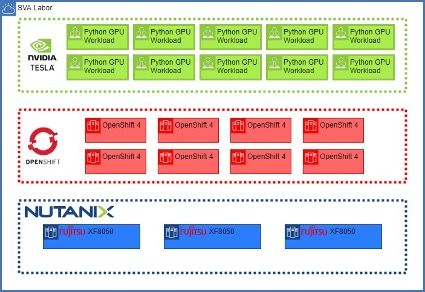
Abb 1.: SVA Labor-Setup
Nutanix Platform bereitstellen
Für das Vorhaben konnte im Testlabor auf Fujitsu Hardware zurückgegriffen werden. Aus den in der Tabelle aufgeführten Komponenten konnten aus 3 Nodes ein Cluster mit 172 GHz verteilt auf 72 CPUs Cores, 1,5 TB RAM, und 23 TB SSDSpeicher bereitgestellt werden. Die Nodes wurden dabei von insgesamt 3 x NVIDIA Tesla T4-GPU beschleunigt. Mit der Nutanix Installation ist es nun möglich, die Umgebung komfortabel zu nutzen und später einfach zu skalieren.
| Typ | Bezeichnung | Menge |
| Node Chassis | XF8050NVME-M2 Core | 3 |
| OOB Management | iRMC Advanced Pack | 3 |
| Netzteil | Modulare SV 800W Platinum hp | 6 |
| CPU | Intel Xeon Silver 4214R 12C 2.40 GHz | 6 |
| RAM | 32GB (1x32GB) 2Rx4 DDR4-2933 R ECC | 48 |
| NVMe | SSD PCIe3 1.92TB Mixed-Use 2.5′ H-P EP | 12 |
| Netzwerk | PLAN EP X710-DA2 2x10Gb SFP+ LP | 3 |
| GPU | T4 | 3 |
OpenShift Installation
„Sharing is caring“, durch die Vorarbeit von SVA-Kolleg:innen lag bereits eine automatisierte Lösung für eine OpenShift-Installation vor, welche schon im Blog-Beitrag Red Hat OpenShift & Nutanix AHV – SVA Style beschrieben wird. Nach knapp 40 Minuten stand der fertig installierte OpenShift Cluster und die NVIDIA-Arbeiten konnten beginnen.
NVIDIA-Installation
Zunächst wurden den OpenShift Worker Nodes eine GPU zugeordnet. Dank der Nutanix Plattform konnte dieser Schritt in wenigen Sekunden automatisiert via Script erledigt werden. Nach einer kurzen Boot-Phase waren die Nodes im OpenShift Cluster dann wieder verfügbar. Im nächsten Schritt wurde der Node Feature Discovery Operator aus dem OpenShift OperatorHub installiert, welcher die Hardware-Features, der im Cluster verfügbaren Nodes erkennt.
Während der ersten, noch manuellen Installation, wurde der von NVIDIA angebotenen Operator aus dem OperatorHub direkt installiert. Da der OpenShift Cluster in der Lab-Umgebung auf virtuelle Maschinen von Nutanix AHV setzt, stehen hier sogenannte vGPUs zur Verfügung. Mittels vGPUs ist es möglich eine Hardware GPU Karte über das Feature Multi-Instance GPU (MIG) zu partitionieren um die daraus resultierenden Instanzen als virtuelle Ressourcen an die VM weiterzugeben.
Da dem im OperatorHub angebotenen Operator Image die vGPU Unterstützung fehlt, bestand die Notwendigkeit, den Treiber selbst zu bauen. Zunächst musste dafür der NVIDIA Treiber als Binary aus dem Partnerportal heruntergeladen werden.
Dieser Treiber wurde anschließend Teil eines neuen Containerimages welches via HelmChart im OpenShift Cluster installiert wurde. Dank des Node Discovey Operators stand der clusterweiten Aktivierung der GPU-Beschleunigung nun nichts mehr im Wege.
Automatisierte Installation des vGPU-Treibers:
- Installation des Node-Feature-Discovery-Operators
- Bauen des Containers mit NVIDIA-Binärtreiber
- Hochladen des Treibers in eine Container-Registry
- Helm-Deployment mit Verweis auf Container-Registry
- Deployment eines Test-Containers
Abb 2.: Demo Operator Installation + GPU Driver Container
GPU Workload
Um die GPU-Beschleunigung des OpenShift Clusters zu demonstrieren, wurde auf Jupyterlab gesetzt. Hierzu wurden drei passende Codebeispiele erzeugt. Für diese Szenarien kommen die Python Libraries NumPy & PyTorch zum Einsatz. Während NumPy für wissenschaftliche Berechnungen gedacht ist, ist PyTorch eine auf Deep Learning ausgerichtete Bibliothek. Ziel dieser Demo ist es, die Ausführungszeiten auf CPU und GPU gegenüberzustellen, sie zu vergleichen und die Unterschiede visualisieren zu können.
Abb 3.: Figure 1 Jupyterlab auf OpenShift
Im ersten Beispiel wird mithilfe von NumPy eine Matrixoperation ausgeführt. Diese wird mit der PyTorch Library wiederholt, um die Libraries miteinander vergleichen zu können. Anschließend werden die Berechnungen mit GPU Unterstützung ausgeführt.
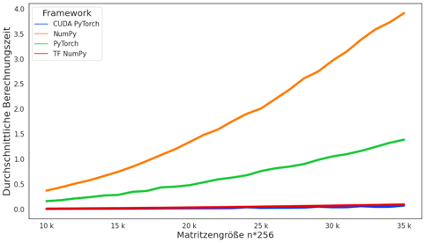
Abb 4.: Berechnungszeit vs. Matritzengröße Chart
Vergleicht man die Werte der kleinen „Hello GPU World“-Anwendung, lässt sich das Potential bei der Verarbeitung größerer Datenmengen erahnen. In dem Beispiel konnte die Ausführungszeit von 3 Sekunden (Numpy on CPU), auf ~0,04 Sekunden (PyTorch on GPU) minimiert werden, ein Faktor von 75.
| Framework | Größe n*256 | Sekunden |
| NumPy (CPU) | 10000 | 0.370017 |
| 20000 | 1.340.759 | |
| 30000 | 2.967.670 | |
| PyTorch (CPU) | 10000 | 0.160944 |
| 20000 | 0.478665 | |
| 30000 | 1.053.954 | |
| TF NumPy (GPU) | 10000 | 0.010490 |
| 20000 | 0.032914 | |
| 30000 | 0.070088 | |
| CUDA PyTorch (GPU) | 10000 | 0.005151 |
| 20000 | 0.017074 | |
| 30000 | 0.038 |
Abb 5.: Berechnungszeit vs. Matritzengröße Messwerte
Fazit
RedHat OpenShift stellt in Kombination mit der Nutanix HCI-Plattform eine passgenaue Management-Umgebung für eine Platform-as-a-Service-Anwendung dar. Die Verwaltung der GPU-Ressourcen wurde durch OpenShift-Bordmittel stark vereinfacht, sodass die Möglichkeiten der Skalierung für verschiedenartige User-Workloads zukünftig voll ausgeschöpft werden können. Die Segmentierung der Hardware ermöglicht es zudem, die Workloads entsprechend zu isolieren, sowie diese effizient und kostengünstig zu betreiben.
After seeing their colleagues‘ initial success performing an automated installation of OpenShift based on Nutanix, SVA’s NVIDIA technical department took notice.
„Problems are opportunities and within every opportunity new problems arise.“ is a nice quote. Opportunities like this can be used to face the problems. Together with colleagues we can find solutions and develop them further. With the foundation of the partnership with NVIDIA and a ready installed OpenShift environment based on Nutanix AHV, an idea emerged: the work in the SVA Lab started with an internal hackathon.
Idea
The basic characteristics of the intended goal can be described as follows:
To reduce complexity and to make the solution easier to manage, the ideal target environment describes a supported all-in-one enterprise solution based on Nutanix AHV, OpenShift and NVIDIA Grid GPUs. In order to optimally combine the products, the installation process of all components should be reproducible and automated. This is backed by the Nutanix HCI platform which enables scaling up as easy as possible at the infrastructure level. To ensure that microservice applications can be deployed without restrictions, OpenShift is used as the container platform, which can also be scaled easily. Once the automation of the stack is complete, the resulting infrastructure empowers the hardware and microservices orchestrated by OpenShift to scale cost-effectively with the simplest of means.
Fig 1.: SVA Lab-Setup
Deploy Nutanix Platform
For the project, existing Fujitsu hardware was available in the test lab for use. From the components listed in the table below, a cluster with 172 GHz distributed over 72 CPUs cores, 1.5 TB RAM, and 23 TB SSD storage could be provided from the 3 nodes. The nodes were equipped with a total of 3 x NVIDIA Tesla T4 GPU. With the Nutanix installation running on the nodes, managing and scaling the environment was much simpler.
| Typ | Description | Value |
|---|---|---|
| Node Chassis | XF8050NVME-M2 Core | 3 |
| OOB Management | iRMC Advanced Pack | 3 |
| Netzteil | Modulare SV 800W Platinum hp | 6 |
| CPU | Intel Xeon Silver 4214R 12C 2.40 GHz | 6 |
| RAM | 32GB (1x32GB) 2Rx4 DDR4-2933 R ECC | 48 |
| NVMe | SSD PCIe3 1.92TB Mixed-Use 2.5′ H-P EP | 12 |
| Netzwerk | PLAN EP X710-DA2 2x10Gb SFP+ LP | 3 |
| GPU | T4 | 3 |
OpenShift Installation
„Sharing is caring“, through the preliminary work of SVA colleagues an automated solution for an OpenShift installation was already available, which is already described in the blog post Red Hat OpenShift & Nutanix AHV – SVA. After just under 40 minutes, the fully installed OpenShift cluster was up and running and the NVIDIA work could begin.
NVIDIA installation
First, GPUs were assigned to the OpenShift worker nodes. Thanks to the Nutanix platform, this step could be automated via script in a few seconds. After a short boot phase, the nodes were then available in the OpenShift cluster. The next step was to install the Node Feature Discovery Operator from the OpenShift OperatorHub, which detects the hardware features of the nodes available in the cluster.
During the first manual installation, the operator offered by NVIDIA from the OperatorHub was installed directly. Since the OpenShift cluster in the lab environment relies on Nutanix AHV virtual machines, so-called vGPUs are available here. Using vGPUs, it is possible to partition a hardware GPU card via the Multi-Instance GPU (MIG) feature in order to pass the resulting instances to the VM as virtual resources.
Since the operator image offered in OperatorHub lacks vGPU support, there was a need to build the driver ourselves. First, the NVIDIA driver had to be downloaded as a binary from the partner portal.
This driver then became part of a new container image which was installed via HelmChart in the OpenShift cluster. Thanks to the Node Discovey operator, nothing now stood in the way of cluster-wide activation of GPU acceleration.
Automated installation of the vGPU driver:
- Installing the Node Feature Discovery Operator
- Building the container with NVIDIA binary driver
- Uploading the driver to a container registry
- Helmet deployment with reference to container registry
- Deployment of a test container
Fig 2.: Demo Operator Installation + GPU Driver Container + Jupyterlab Demo
GPU Workload
To demonstrate the GPU acceleration of the OpenShift cluster, we relied on Jupyterlab. For this purpose, three suitable code examples were generated. For these scenarios, the Python libraries NumPy & PyTorch were used. While NumPy is intended for scientific computations, PyTorch is a library geared towards Deep Learning. The goal of this demo is to contrast the execution times on CPU and GPU, compare them and be able to visualize the differences.
Figure 3: Figure 1 Jupyterlab on OpenShift
In the first example, a matrix operation is performed using NumPy. This is repeated using the PyTorch library to compare the libraries. Then, the calculations are performed with GPU support.
Fig. 4.: Computation time vs. matrix size chart
Comparing the values of the small „Hello GPU World“ application, one can get an idea of the potential when processing larger data sets. In the example, the execution time could be minimized from 3 seconds (Numpy on CPU), to ~0.04 seconds (PyTorch on GPU), a factor of 75.
| Framework | Size n*256 | Seconds |
| NumPy (CPU) | 10000 | 0.370017 |
| 20000 | 1.340.759 | |
| 30000 | 2.967.670 | |
| PyTorch (CPU) | 10000 | 0.160944 |
| 20000 | 0.478665 | |
| 30000 | 1.053.954 | |
| TF NumPy (GPU) | 10000 | 0.010490 |
| 20000 | 0.032914 | |
| 30000 | 0.070088 | |
| CUDA PyTorch (GPU) | 10000 | 0.005151 |
| 20000 | 0.017074 | |
| 30000 | 0.038 |
Fig. 5: Calculation time vs. matrix size measured values
Conclusion
RedHat OpenShift, in combination with the Nutanix HCI platform, provides a fit for purpose management environment for Platform-as-a-Service applications. GPU resource management has been greatly simplified through OpenShift features , allowing full scaling capabilities for diverse user workloads in the future. Hardware segmentation also enables workloads to be appropriately isolated, as well as run efficiently and cost-effectively.