
Private Cluster = private Applikationen?
Dies ist der dritte Teil der Artikelreihe zum Thema „Private Kubernetes-Cluster in der Azure Public Cloud“. Nachdem wir uns in Teil 1 mit der Architektur und in Teil 2 mit der Bereitstellung der Infrastruktur beschäftigt haben, widmen wir uns in diesem Teil den Applikationen, die wir in unseren privaten AKS-Cluster ausliefern und betreiben wollen. Dabei müssen wir beachten, dass der Kubernetes API-Server ausschließlich über einen privaten Endpunkt erreichbar ist.
Zunächst sollte klargestellt werden, dass die Erreichbarkeit des API-Servers unabhängig von der Zugänglichkeit der Applikationen im Cluster ist. Auch wenn der Kubernetes API-Server ausschließlich über einen privaten Endpunkt erreichbar ist, können die Applikationen öffentlich verfügbar sein. Das nachfolgende Schaubild zeigt eine mögliche Architektur, in der eine Applikation über zwei unterschiedliche Wege zugänglich ist. Während Entwickler über eine private Verbindung (orange markiert) auf die Applikation zugreifen, nutzen Endnutzer einen öffentlichen Weg (grün markiert). Für die Domain „myapp.com“ gibt es eine öffentliche und eine private DNS-Zone („Split-DNS“).
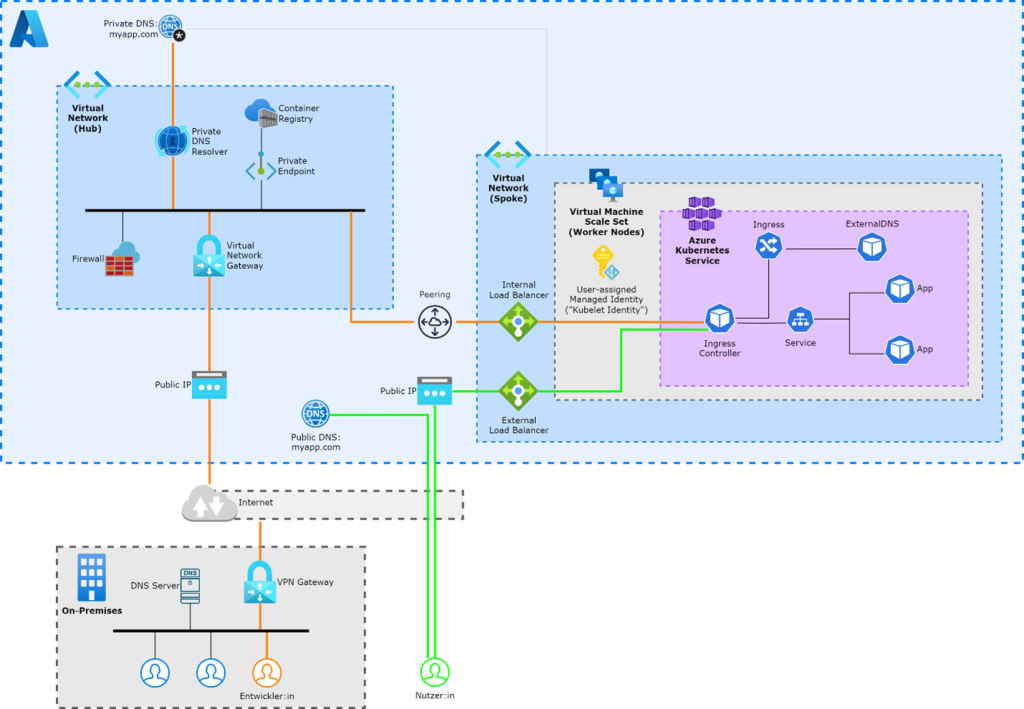
Bevor wir uns jedoch um die Erreichbarkeit der Applikation(en) über öffentliche oder private Netzwerke Gedanken machen, gehen wir in diesem Teil der Artikelreihe zunächst einen Schritt zurück und stellen uns die Frage: Wie kann eine Applikation in einem privaten Cluster bereitgestellt werden?
Inwieweit auch private Endpunkte für die Applikationen im AKS-Cluster genutzt werden können, schauen wir uns im nachfolgenden Teil näher an.
Continuous Delivery mit Azure DevOps
Sofern unsere Applikation kontinuierlich weiterentwickelt wird und regelmäßig neue Versionen erscheinen, sollte der Bereitstellungsprozess automatisiert werden („Continuous Delivery“ oder „Continuous Deployment“). Die Bereitstellung einer Applikation läuft meist nach folgendem Schema ab:
- Es wird ein Ereignis/Event ausgelöst. Dieses Ereignis kann beispielsweise eine Veränderung eines Git-Branches, ein Pull-Request oder auch eine manuelle Aktion eines Benutzers sein.
- Das Ereignis löst eine oder mehrere Aktionen aus.
- Die Aktionen werden auf einem dafür vorgesehenen System ausgeführt.
Der Bereitstellungsprozess wird somit nicht durch eine natürliche Person auf einer persönlichen Workstation, sondern durch eine technische Identität auf einem dafür vorgesehenen System ausgeführt.
In dieser Artikelreihe fokussieren wir uns auf das Produkt „Azure DevOps“ aus dem Hause Microsoft als Tool für die Automatisierung der Bereitstellung von Applikationen. In diesem Kontext wird das zuvor be-schriebene System als „Agent“ bezeichnet. Die grundsätzliche Vorgehensweise ähnelt der Nutzung anderer Tools wie GitHub oder GitLab jedoch stark. Die Nutzung anderer Methodiken und Tools wird im letzten Abschnitt dieses Artikels kurz angesprochen.
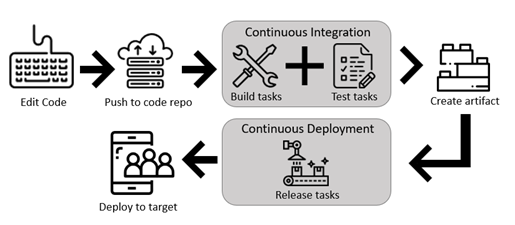
Pipeline Jobs und Tasks
Der Bereitstellungsprozess setzt sich aus mehreren Schritten zusammen, die in Azure DevOps als „Steps“ oder „Tasks“ definiert werden. Schritte, die sequenziell abgearbeitet werden müssen, können zu „Jobs“ zusammengefasst werden. Jobs, zwischen denen keine Abhängigkeiten bestehen, können parallel ausgeführt werden. Jobs werden wiederum zu Pipelines zusammengeschlossen. Eine Pipeline beinhaltet somit mindestens einen Job mit mindestens einem Task. Das Ziel der Ausführung der Pipelines ist in unserem Fall, dass die Applikation in unserem AKS-Cluster läuft und voll funktionsfähig ist.
Azure Pipeline Agents
Für die Bereitstellung der Applikation benötigen wir einen oder mehrere „Pipeline Agents“. Ein Agent ist ein System, das alle Anforderungen für die Ausführung von automatisierten Prozessen erfüllt. Dies ist in diesem Fall die Bereitstellung einer Applikation in Kubernetes. Zu diesen Anforderungen zählen beispielsweise Rechenleistung und Speicherkapazität für die Ausführung der Pipelines und das Vorhandensein von verschie-denen Softwarepaketen.
Folgende Voraussetzung muss in unserem Fall darüber hinaus immer erfüllt werden: Der Agent benötigt Zugriff auf den privaten Endpunkt der Kubernetes API, um Applikationen bereitstellen zu können. Grund-sätzlich bietet Azure DevOps zwei Optionen für das Hosting der Agents, die wir uns nachfolgend näher ansehen. Wir können die Agents entweder von Microsoft hosten lassen oder selbst hosten.
Von Microsoft gehostete Agents
Von Microsoft gehostete Agents werden bei Bedarf – also sobald ein Job ausgeführt werden soll – durch Microsoft bereitgestellt und nach Abschluss des Jobs wieder deprovisioniert. Der Vorteil liegt in dem reduzierten Aufwand für die Verwaltung des Agents, da dieser zu Microsoft ausgelagert werden kann. Viele Softwarepakete sind bereits vorinstalliert. Je nach Bedarf können weitere Softwarepakete als Teil einer Pipeline nachinstalliert werden.
Während der reduzierte Verwaltungsaufwand zwar einen Vorteil darstellt, haben wir in unserem Szenario jedoch folgendes Problem: Die Agents werden durch Microsoft betrieben und sind somit netzwerktechnisch von unseren Azure-Ressourcen getrennt. Es ist nicht möglich einen von Microsoft gehosteten Agent in ein eigenes virtuelles Netzwerk in Azure zu integrieren.
Daher gilt grundsätzlich: Sofern der API-Server privat ist, können von Microsoft gehostete Agents nicht für die Auslieferung von Software in den AKS-Cluster genutzt werden, da sie den privaten Endpunkt des API-Servers nicht erreichen können. Stattdessen müssen wir die Agents selbst bereitstellen und betreiben – in diesem Fall sprechen wir von selbst gehosteten Agents“.
Selbst gehostete Agents
Ein selbst gehosteter Agent basiert auf derselben Software wie ein von Microsoft gehosteter Agent, wir müssen diese jedoch auf einem eigenen System selbst installieren und betreiben. Das Hosting des Agents kann auf einer physischen oder virtuellen Maschine (VM) oder auch auf einem Container basieren. Die Agent-Software wird von Microsoft bereitgestellt und kann installiert oder zu einem Container Image hin-zugefügt werden.
Der Agent kann grundsätzlich in jedem Netzwerk platziert werden, von dem aus Verbindungen zu der API des AKS-Clusters möglich sind. Eine netzwerktechnisch einfache Methode ist es, den Agenten als Container in AKS zu betreiben oder in einem Subnetz des AKS-Netzwerks zu platzieren. So kann der Agent die API direkt erreichen. Alternativ kann dieser in einem dedizierten virtuellen Netzwerk in Azure platziert werden. Dieses Netzwerk muss dann mittels „Network Peering“ an das AKS-Netzwerk angebunden werden.
Der Agent kann aber auch bei einem anderen Cloud Provider oder in einem lokalen Unternehmensnetzwerk betrieben werden, solange Verbindungen zu dem virtuellen Netzwerk in Azure möglich sind (z. B. via VPN).
Managed Identity Authentifizierung
Sofern wir Agents in Azure betreiben und die Integration unseres AKS-Clusters in das Azure Active Directory bzw. Microsoft Entra IDhttps://learn.microsoft.com/en-us/azure/aks/enable-authentication-microsoft-entra-id aktiviert ist, bietet es sich an, sogenannte „Managed Identities“ für die Authentifi-zierung am Kubernetes API-Server und somit für die Bereitstellung von Applikationen im Cluster zu nutzen.
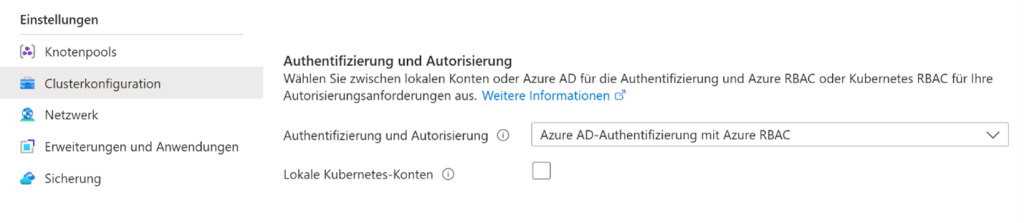
Hierfür können wir die jeweilige Identität auf den gesamten Cluster oder auf bestimmte Namespaces be-rechtigen. Die Berechtigung auf einzelne Namespaces ist jedoch aktuell noch nicht über das Azure Portal, sondern nur mit der Azure CLI oder anderen Tools, die die Azure Resource Manager API nutzen (z. B. Hashi-Corp Terraform), möglich (Stand: März 2024).
Sofern wir einen Agent beispielsweise auf einer virtuellen Maschine in Azure betreiben, können wir dieser VM eine „Managed Identity“ zuweisen. Diese kann entweder systemseitig oder benutzerseitig zugewiesen werden. Eine benutzerseitig zugewiesene Identität kann auch mehreren VMs zugewiesen werden.
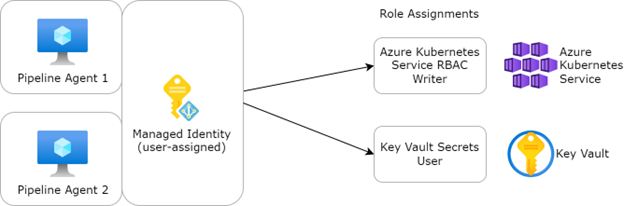
Zur Nutzung dieser Authentifizierungsmethode muss in Azure DevOps eine Service Connection vom Typ „Azure Resource Manager“ mit der Authentifizierungsmethode „Managed Identity“ erstellt werden. Pipe-lines, die von einem selbst gehosteten Agent ausgeführt werden und diese Service Connection nutzen, können sich dann mit der „Managed Identity“ authentifizieren.
Anschließend können wir eine Pipeline definieren. In dieser geben wir den Agent Pool an, zu dem wir unse-re selbstverwalteten Agents hinzugefügt haben. Außerdem definieren wir Tasks, beispielsweise basierend auf den integrierten Tasks für kubectl und Helm. In den Tasks geben wir die zuvor erstellte Service Connection an, um diese für die Bereitstellung der Applikation zu verwenden. Wir haben nun also eine Pipeline, über die wir Applikationen in unseren privaten AKS-Cluster ausrollen können.
Ausblick: GitOps als alternative Methodik
In diesem Artikel haben wir uns auf die Bereitstellung von Anwendungen mit Hilfe von Azure DevOps Pipelines fokussiert. An dieser Stelle soll eine etwas andere Methodik zumindest erwähnt werden: GitOps.
Diese Methodik wurde ursprünglich primär für Kubernetes entwickelt, kann aber auch in anderen Bereichen angewendet werden. Hierbei steht ebenfalls das Versionsverwaltungssystem Git im Mittelpunkt. Ein Repository dient als „single source of truth“, der gewünschte Zielzustand des Clusters (oder eines einzelnen Namespaces) wird also in Git gepflegt. Azure DevOps bzw. Azure Repos können also auch bei dieser Methodik eingesetzt werden.
Im Gegensatz zu der zuvor beschriebenen Vorgehensweise werden für die Bereitstellung von Applikationen keine Pipelines verwendet. Stattdessen werden in Kubernetes Software-Agenten betrieben, die den beschriebenen Zielzustand in Git mit dem tatsächlichen Zustand vergleichen. Sofern Unterschiede vorliegen, wird der Zustand des Clusters so angepasst, dass dieser dem Zielzustand entspricht. Genehmigte Änderungen (Pull Requests) werden somit automatisch auf den Kubernetes-Cluster angewendet.
Um den Rahmen dieses Artikels nicht zu sprengen, verweisen wir an dieser Stelle auf unseren Podcast „Focus on DevOps“. Bei Interesse geben wir Ihnen in der Folge „E30 – GitOps“ weitere Einblicke in die GitOps-Methodik.
Zusammenfassung
In diesem Teil der Artikelreihe haben wir betrachtet, was bei der Auslieferung von Applikationen in einen privaten AKS-Cluster beachtet werden muss. Entscheidend ist hierbei, dass das System, welches den Auslieferungsprozess ausführt, den Kubernetes API-Server erreichen kann. Sofern sich das System nicht innerhalb des Clusters befindet, muss also für Netzwerkkonnektivität zwischen dem System und dem virtuellen Netzwerk in Azure gesorgt werden.
Auch die Applikationen können über private Endpunkte zugänglich gemacht werden, sodass der Zugriff aus dem Internet nicht möglich ist. Hierauf werden wir im nächsten Teil der Artikelreihe näher eingehen.