
IoT – a hype becoming reality?
During the last years, Internet of Things or IoT became widely recognized across the world as a mega trend of interconnecting everyday objects by embedding tiny computing devices into everyday objects, enabling them to collect, process and exchange data. To put it in a more general context, IoT is an ecosystem of devices exchanging information. Yet for the future, potential capabilities are considered even more promising. According to the conception of industry leaders, the world of tomorrow is displayed as a wonderland of technical blessings. By connecting billions of devices, IoT is supposed to enable smart services across multiple industries, from the public sector and healthcare to retail to manufacturing and several more.
However, for this vision to become reality and add value to our everyday lives, there is still a rocky road ahead. A foundational infrastructure must be provided to enable the flow of data and then analysis must be provided to gain meaningful insights from it. There is a need to break open data silos and connect modern IoT communication technology with strong analytics tech.
The question: How to get IoT Data from HiveMQ into Splunk?
Concerning the collection of IoT Data, lightweight, event-driven architectures are used to exchange data in an efficient and secure manner. A prime example is Message Queuing Telemetry Transport (MQTT), which has evolved into the de-facto standard protocol for machine data. Device-Clients publish data to a Broker via MQTT-Topics, where it is distributed to other clients that subscribe to the Topics. HiveMQ delivers enterprise-ready implementation of an MQTT-Broker, by integrating state-of-the-art features for security and scalability into the product as well as providing hosting and support options for production-grade operations. On the analytics side, Splunk is one of the leading platforms for analytics, ranging from all kinds of data mining-techniques such as data transformation and processing, visualizations or statistical functions to complex machine learning algorithms and neural networks. Hence, there are already very sophisticated solutions available, both for collecting data from connected devices, as well as for processing and analysis of that data. Thus, the challenge at hand is one of integrating these two systems together.
The answer: Break silos, build bridges!
In order to enable a smooth transmission of IoT Data between both systems, we at SVA built an extension that can natively be plugged into HiveMQ as a data bridge to Splunk. This way it is possible to seamlessly integrate advanced analytics into an existing IoT infrastructure and take advantage of many of HiveMQs enterprise-grade features out of the box. By forwarding messages from HiveMQ to the HTTP Endpoint Collectors (HECs) of a Splunk Cluster instantaneously or in batches, the HiveMQ – Splunk extension makes it possible to monitor any kind of connected devices such as industrial equipment or transport vehicles. The collected data can be processed and visualized using Splunk’s rich set of data manipulation and dashboarding features. For larger datasets and advanced analytics, custom machine learning applications can be built on top. In addition, the extension is able to send operational metrics from the HiveMQ-Broker itself to Splunk, enabling administrators to always be informed about the current state of their HiveMQ-Cluster as a critical piece of IoT infrastructure. This allows for enhanced application performance monitoring with immediate alerts as well as quick and precise reactions to downtimes or bottlenecks.
The image below illustrates the routing of IoT data from any kind of connected devices, to the HiveMQ-Cluster, which forwards it via the HiveMQ-Splunk-Extension to a Splunk HTTP Endpoint Collector.
Here, the data is indexed and can be processed for powering applications that generate business-relevant insights.
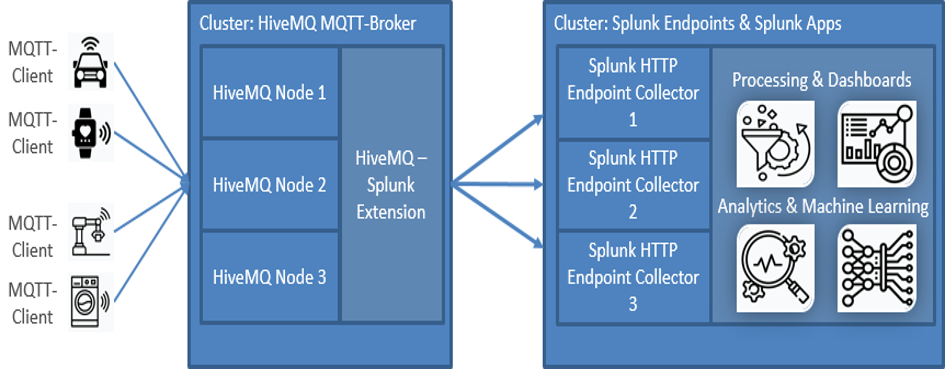
MQTT-Data flow with the HiveMQ-Splunk Extension: Device data collected by HiveMQ is pushed to the Splunk HTTP Endpoint Collector. In Splunk, all kinds of data-driven applications can be leveraged.
Production-ready for distributed and volatile ecosystems
The SVA extension from HiveMQ to Splunk is able to handle thousands of messages per second and performs stable even in highly volatile environments with fast changing numbers of clients as well as in hybrid- or multi-cloud architectures. Transmitters can operate independently from each other, which allows for multi-threading and vertical scalability. In case of a temporary unavailability of a Splunk HEC, messages are buffered and requeued in order to send them to another endpoint or at a later point in time, thus minimizing potential loss of information. Since the extension can be integrated natively into the HiveMQ-Broker, it directly benefits from the horizontal scalability and other enterprise features of HiveMQ. Allowing Splunk to constantly monitor the health and performance of every instance of HiveMQ improves operational modes as well as response times to incidents.
Establishing common standards is key
Message brokers such as HiveMQ can serve as central points of communication by establishing a link not only between connected devices and IT-Infrastructure, but also by breaking open silos within existing system landscapes or microservice architectures. Bridging the gap between the initial ingestion of IoT data and analytical applications is fundamental for more complex, innovative services, which rely on historical as well as on real-time data, such as predictive maintenance or digital twins.
Along with increasing interconnectedness comes the need for interoperability across levels of the automation pyramid and even beyond company borders. Ultimately, even with ubiquitous connectivity and artificial intelligence, the future of (Industrial) IoT cannot unfold, as long as most manufacturing systems are silo-solutions, incapable of value extraction throughout the chain. Today’s intelligent assets must become part of tomorrow’s intelligent ecosystems to interact with each other. True interoperability can be achieved only through the industry-wide adoption of interface standardization efforts such as the OPC UA Companion Specification or MQTT Sparkplug B, complemented by common service semantics and annotation models. First when flexible vertically and horizontally integrated scenarios have become possible, smart services based on IoT and analytics can effectively be cast into novel collaborative business models and will fully come to fruition at scale.
Upcoming in part 2: Hands-on Example
In the next part of this little series we will show you how to leverage HiveMQ, our extension and Splunk with IoT Data to keep track of the state of an industrial production line.
Co-Authors:
André Wohnsland
Dominik Pilat
Falk Flößel
Credits for Icons used in the graphic. Icons made by:
https://www.flaticon.com/authors/fjstudio
https://www.flaticon.com/authors/becris
https://www.flaticon.com/authors/mynamepong
https://www.flaticon.com/authors/icongeek26
https://www.flaticon.com/authors/eucalyp
https://www.flaticon.com/authors/freepik