
In den Blogeinträgen zur semantischen Suche https://focus.sva.de/semantische-suche-mit-bert/ wurde gezeigt, wie dynamisch und rapide sich Natural Language Processing (NLP) in den letzten Jahren entwickelt hat. Transformer-Modelle, die seit der Veröffentlichung von Google‘s BERT (Ref: https://arxiv.org/pdf/1810.04805.pdf) den NLP-Bereich dominieren, sind besonders gut darin, kontextuelle Informationen zu nutzen, um bessere Antworten auf Suchanfragen zu finden, Texte zu übersetzen oder deren Inhalte zusammenzufassen. Eine Stärke dieser Modelle, die im letzten Jahr mehr Aufmerksamkeit auf sich zog, ist die Möglichkeit des Transfer-Lernens und vor allem das sogenannte Zeroshot Learning. Erst Mitte Oktober 2021 wurde das englischsprachige T0 Modell veröffentlicht, das gerade sehr gute Ergebnisse liefert und NLP-Expert:innen begeistert, da solche Zeroshot Modelle sehr viel Anwendungsgebiete, wie z.B. Themen-, Sentiment- oder emotionale Klassifikation, abdecken können, ohne dass man sie vorher kostspielig trainieren muss.
Was ist Zeroshot Learning?
Unter Zeroshot Learning verstand man ursprünglich, dass ein Modell auf einem gelabelten Datenset trainiert und anschließend mit einem neuen Set an Labels, die das Model vorher noch nicht gesehen hat, evaluiert wird. Die Krux: Kann das Modell das Gelernte auf den neuen, unbekannten Kontext transferieren? Im NLP-Bereich wurde die Verwendung des Begriffes sogar erweitert: Kann man ein Modell für eine Aufgabe verwenden, für die es gar nicht trainiert wurde?!
(Ref: https://joeddav.github.io/blog/2020/05/29/ZSL.html). Hier hat sich in den letzten Jahren viel getan, besonders mit Hilfe von Natural Language Inference (NLI) Modellen.
Natural Langue Inference
Das Training eines NLI-Modells selbst funktioniert denkbar einfach: Dem Modell werden immer zwei Sätze geliefert und es soll lernen, ob der erste Satz (die Prämisse), dem zweiten Satz (die Hypothese):
1) inhaltlich „widerspricht“ (engl. „contradiction“),
2) dem zweiten Satz gegenüber „neutral“ ist oder
3) den zweiten Satz nach sich zieht, bzw. zur Konsequenz hat (engl. „entailment“)

Zeroshot-Text-Klassifikation
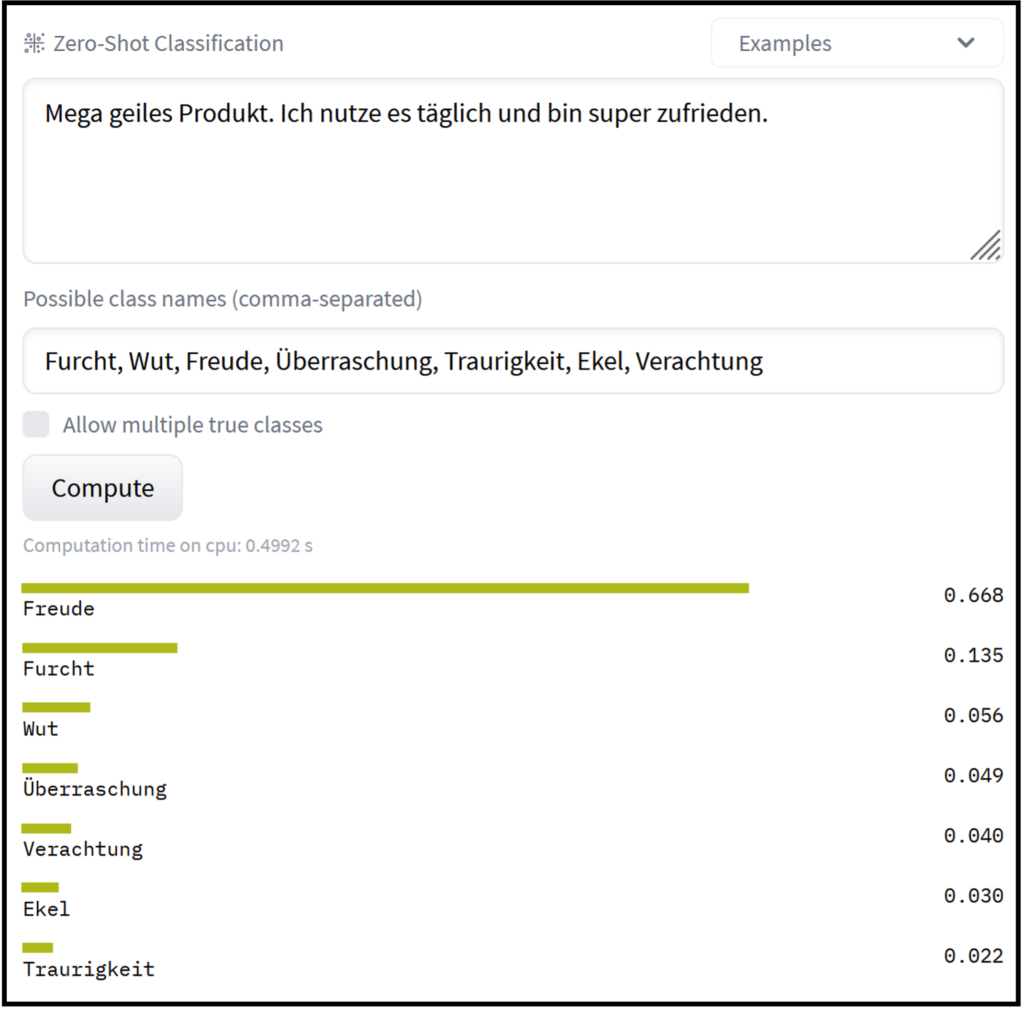
Das Faszinierende: Genau dieses Modell kann ohne weiteres Training genutzt werden, um Zeroshot-Text-Klassifikation durchzuführen, d.h. man kann damit Texte in verschiedene, selbstgewählte Kategorien einordnen lassen. Technisch vergleicht das Modell die zu klassifizierenden Texte paarweise mit allen Kategorien, die in Satzform an das Modell gegeben werden (z.B. „In diesem Satz geht es um das Thema Handy“). Zur Evaluation wird nun nur noch der „entailment“-Score genutzt, der angibt, wie gut die Sätze zusammenpassen. Und voila, der Satz mit dem höchsten Score wird als passendes Thema vorgeschlagen (Siehe Bild 2 und 3).
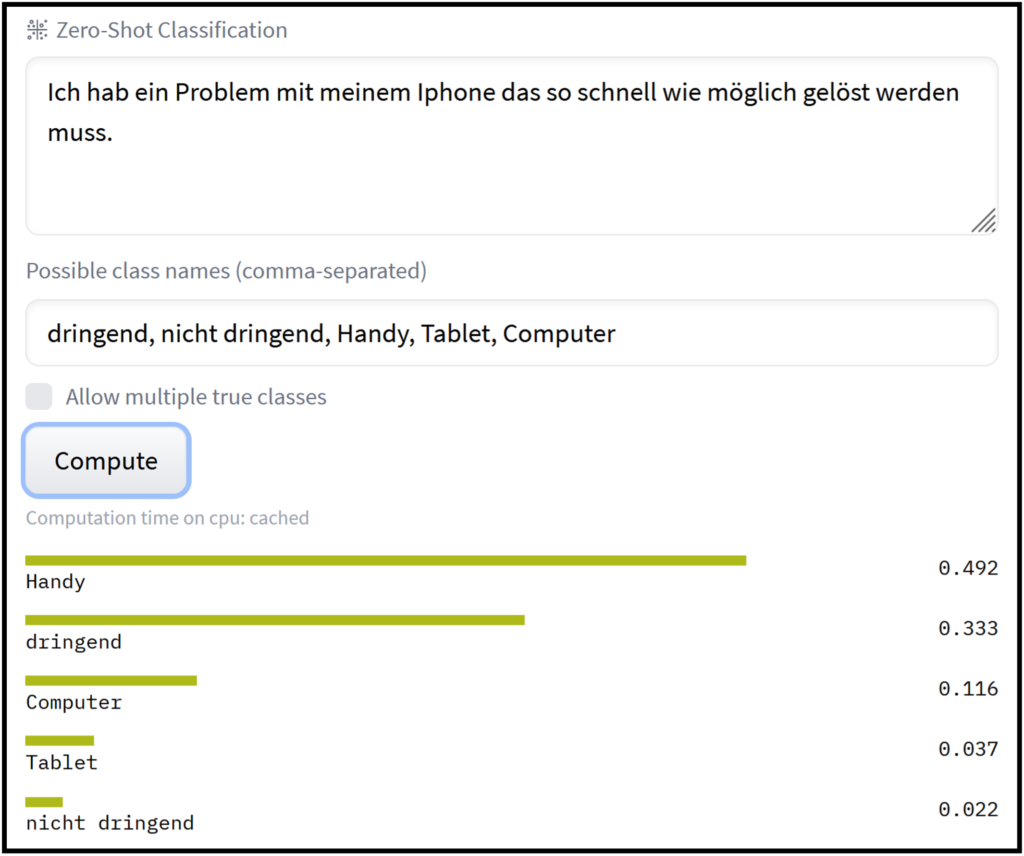
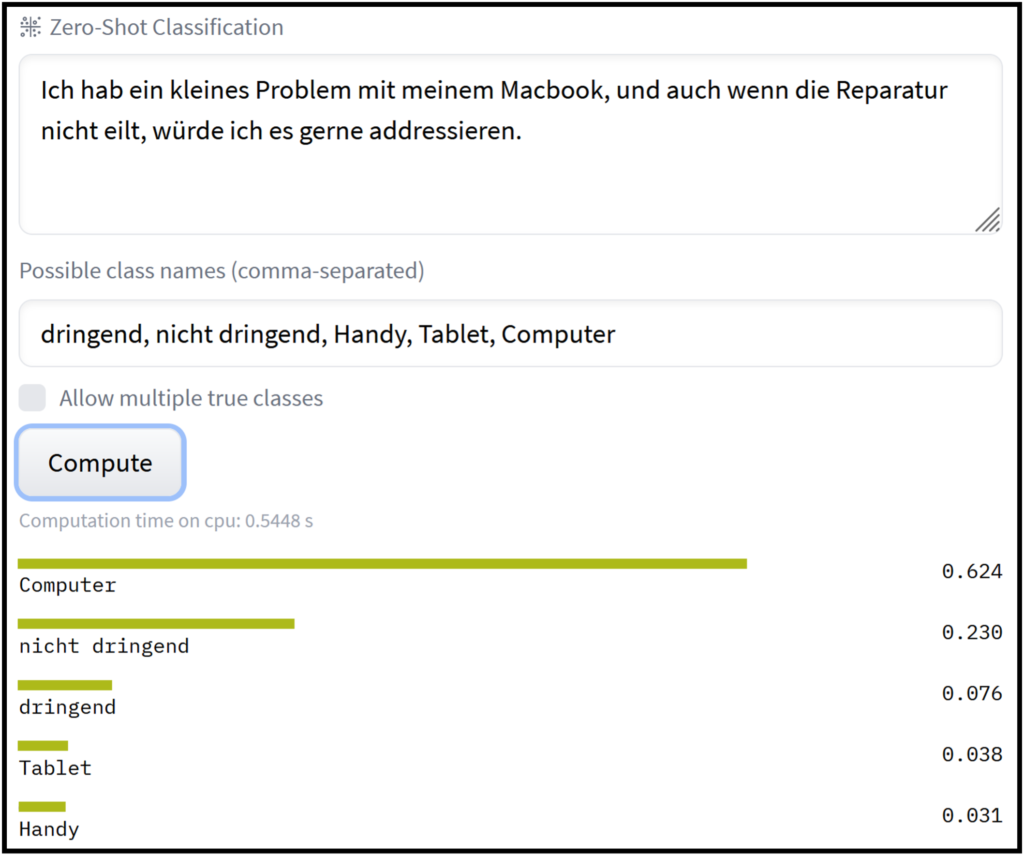
Introducing „svalabs/gbert-large-zeroshot-nli“
Obwohl die Klassifikation auf transfer-learning basiert, können die NLI-Modelle in der Regel verschiedene Sprachen nicht überbrücken und sind meist für die englische Sprache ausgelegt (Beispiele: roberta-large-mnli, bart-large-mnli). Damit die Modelle auch für den deutschen Sprachraum nutzbar sind, musste ein NLI-Modell basierend auf fast einer Million deutschsprachiger Satzpaare trainiert werden.
Dieses vom SVA Data Science Team trainierte Modell steht jetzt auf Hugginface zur freien Nutzung zur Verfügung: https://huggingface.co/svalabs/gbert-large-zeroshot-nli Damit kann jede:r das Modell auch selbst testen und Beispielsätze, Kategorien oder Datensätze damit überprüfen.
Benchmarks
Zur Evaluation des Modells wurde zunächst das Test-Set des deutschen XNLI-Datensets (Ref: https://arxiv.org/pdf/1809.05053.pdf) genutzt, um die NLI-Performance zu testen.
Ergebnis: 86% Richtigkeit (Vergleich German_Zeroshot: 83.6% Richtigkeit)
Um die Performance für Zeroshot-Text-Klassifikation zu evaluieren, wurde der Teil des 10KGNAD Datensatzes genutzt, dessen Label themenbasiert sind. Dem Modell wurden also 5401 Nachrichten-Artikel gezeigt, die jeweils einer von fünf thematischen Gruppen zugeteilt sind (Web, Wirtschaft, Sport, Wissenschaft, Kultur). Das Modell sollte nun vorhersagen, aus welcher der fünf Kategorien ein Artikel stammt, ohne vorher darauf trainiert worden zu sein. Insgesamt hat das Modell für diese Aufgabe die höchste Richtigkeit (den höchsten Anteil an richtig bestimmten Kategorien) verglichen mit den relevantesten deutschsprachigen Alternativen (Siehe Bild 4).
| Method | Accuracy |
|---|---|
| svalab/gbert-large-zeroshot-nli | 0.79 |
| German_Zeroshot | 0.76 |
| Symanto/snli-mnli-anli-xnli | 0.16 |
| gbert-base | 0.65 |
Anwendungsbeispiele
Das Model eignet sich besonders für Situationen, in denen keine gelabelten Trainingsdaten zur Verfügung stehen. Beispielsweise können Nachrichten, Newsfeeds usw. in gewünschte thematische Kategorien vorsortiert werden. In ähnlicher Weise gelingt zum Beispiel auch die thematische Kategorisierung von Kundenreviews/Feedbacks. Das Modell lässt sich aber nicht nur für Text-Klassifikation nutzen (Bild 2 und 3). Es kann zum Beispiel auch zur „query-classification“ verwendet werden. Dabei geht es darum zu erkennen, ob eine Suchanfrage als Frage oder als Schlagwortsuche interpretiert werden soll, um anschließend die Suchergebnisse zu verbessern.
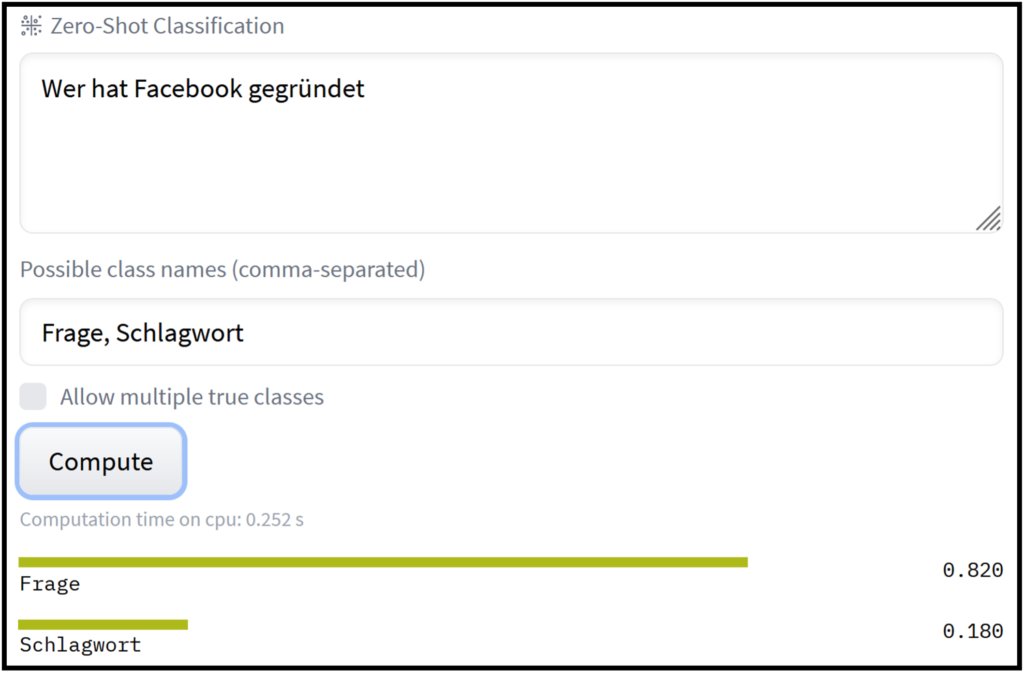
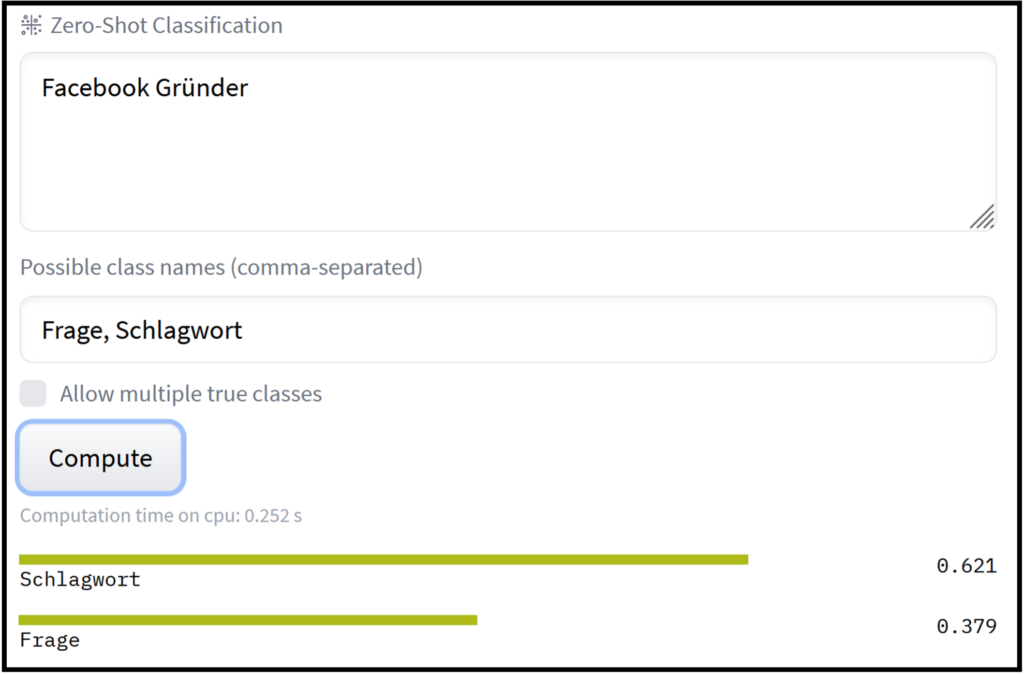
Ein anderer Anwendungsfall entsteht, wenn man daran interessiert ist, welche emotionalen Reaktionen Produkte bei Kunden auslösen (Ref: https://arxiv.org/pdf/1909.00161.pdf). Auch hier kann Zeroshot-Klassifikation einen guten ersten Überblick verschaffen, ganz ohne aufwendiges Training.
Fazit
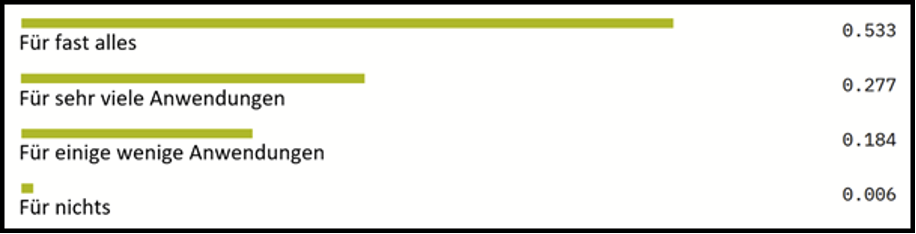
Zeroshot-Modelle sind im NLP-Bereich zunehmend in der Lage Aufgaben zu lösen, für die man bis vor Kurzem noch extra Modelle trainieren musste. Selbst für Anwendungen, für die ein Zeroshot-Modell nicht ausreicht, um gute Ergebnisse zu erzielen, können sie nützlich werden: Wenn Daten beispielsweise manuell gelabelt werden müssen, kann ein Zeroshot-Modell zumindest potentiell sinnvolle Labels vorschlagen (Ref. https://nlp.town/blog/zero-shot-classification/). In jedem Fall bleibt Zeroshot-Learning ein zentrales NLP-Thema und es wird sich in den nächsten Jahren noch einiges tun. Es ist also nur noch eine Frage der Zeit bis Zeroshot-Klassifikations-Modelle die Aussage: „Für was kann man Zeroshot-Klassifikation sinnvoll nutzen?“ wahrheitsgemäß bewerten können mit:
Zeroshot Modell: https://huggingface.co/svalabs/gbert-large-zeroshot-nli